 百木园
百木园本篇重点:
1.HashMap的存储结构
2.HashMap的put和get操作过程
3.HashMap的扩容
4.关于transient关键字
5.HashMap, HashTable, ConcurrentHashMap 对照
6.关于volatile关键字

HashMap的存储结构
1. HashMap 总体是数组+链表的存储结构, 从JDK1.8开始,当数组的长度大于64,且链表的长度大于8的时候,会把链表转为红黑树。
2. 数组的默认长度是16。数组中的每一个元素为一个node,也就是链表的一个节点,node的数据包含: key的hashcode, key, value,指向下一个node节点的指针。
部分源码如下:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } ... }
3. 随着put操作的进行,如果数组的长度超过64,且链表的长度大于8的时候, 则将链表转为红黑树,红黑树节点的结构如下,TreeNode继承的LinkedHashMap.Entry是继承HashMap.Node的,所以TreeNode是上面Node的子类。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; TreeNode(int hash, K key, V val, Node<K,V> next) { super(hash, key, val, next); } //... }
4. HashMap类的主要成员变量:


/* ---------------- Fields -------------- */ /** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table; /** * Holds cached entrySet(). Note that AbstractMap fields are used * for keySet() and values(). */ transient Set<Map.Entry<K,V>> entrySet; /** * The number of key-value mappings contained in this map. */ transient int size; /** * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). */ transient int modCount; /** * The next size value at which to resize (capacity * load factor). * * @serial */ // (The javadoc description is true upon serialization. // Additionally, if the table array has not been allocated, this // field holds the initial array capacity, or zero signifying // DEFAULT_INITIAL_CAPACITY.) int threshold; /** * The load factor for the hash table. * * @serial */ final float loadFactor;
View Code
HashMap的put操作过程
本小节讲述put操作中的主要步骤,细小环节会忽略。
1. map.put(key, value),首先计算key的hash,得到一个int值。
2.如果Node数组为空则初始化Node数组。这里注意,Node数组的长度length始终应该是2的n次方,比如默认的16, 还有32,64等
3.用 hash&(length-1) 运算得到数组下标,这里要提一句,其实正常我们最容易想到的,而且也是我之前很长一段时间以为的,这一步应该进行的是求模运算:hash % length,这样得到的正好是0~length-1之间的值,可以作为数组的下标,那么为何此处是位与运算呢?
先说结论:上面提到数组的长度length始终是2^n,在这个前提下,hash & (length-1) 与hash % length是等价的。 而位与运算更快。这里后面会另开一遍进行详解。
4. 如果Node[hash&(length-1)]处为空,用传入的的key, value创建Node对象,直接放入该下标;如果该下标处不为空,且对象为TreeNode类型,证明此下标处的元素们是按照红黑树的结构存储的,将传入的key,value作为新的红黑树的节点插入到红黑树;否则,此处为链表,用next找到链表的末尾,将新的元素插入。如果在遍历链表的过程中发现链表的长度超过了8,此时如果数组长度<64则进行扩容,否则转红黑树。
5. 如果key的hash和key本身都相等则将该key对应的value更新为新的value
6. 需要扩容的话则进行扩容。
注意:
1. 如果key是null则返回的hash为0,也就是key为null的元素一直被放在数组下标为0的位置。
2. 在JDK 1.8以前,链表是采用的头部插入的方式,从1.8改成了在链表尾部插入新元素的方式。 这么做是为了防止在扩容的时候,多线程时出现循环链表死循环。具体会新开一遍进行详细演绎。
HashMap的get操作过程
get的过程比较简单。
1. map.get(key). 首先计算key的hash。
2. 根据hash&(length-1)定位到Node数组中的一个下标。如果该下标的元素(也就是链表/红黑树的第一个元素)中key的hash的key本身都和传入的key相同,则证明找到了元素,直接返回即可。
3.如果第一个元素不是要找的,如果第一个元素的类型是TreeNode,则按照红黑树的查找方法查找元素,如果不是则证明是链表,按照next指针找下去,直到找到或者到达队尾。
HashMap的扩容
先说这里的两个概念: size, length.
size:是map.size() 方法返回的值,表示的是map中有多少个key-value键值对儿
length: 这里是指Node数组的长度,比如默认长度是16.
如下面的代码:
Map<Integer,String> map = new HashMap<>(); map.put(1,\"a\"); map.put(2,\"b\"); map.put(3,\"c\");
没有在构造函数中指定HashMap的大小,则数组的长度length取默认的16,put了3个元素,则size为3.
Q: 何时需要扩容呢?
A: 在put方法中,每次完成了put操作,都判断一下++size是否大于threshold,如果大于则进行扩容: 调用resize()方法。
Q: 那么threshold又是如何得到的呢?
A: 简单来讲threshold = length * loadfactor(默认为0.75)。 也就是说默认情况下,map中的键值对的个数(size)大于Node数组长度(length)的75%时,就需要扩容了。
Q: 扩容时具体做什么呢?
A: 首先计算出新的数组长度和新的threshold(阈值). 简单来讲,新的length/capacity 是原来的2倍(位运算左移一位),新的threshold为原来的2倍。 还有一些细节此处不再赘述。创建新的Node数组,将原来数组中的元素重新映射到新的数组中。
关于transient关键字
transient关键字的作用:用transient关键字修饰的字段不会被序列化
查看下面的例子:
public class TransientExample implements Serializable{ private String firstName; private transient String middleName; private String lastName; public TransientExample(String firstName,String middleName,String lastName) { this.firstName = firstName; this.middleName = middleName; this.lastName = lastName; } @Override public String toString() { StringBuilder sb = new StringBuilder(); sb.append(\"firstName:\").append(firstName).append(\"\\n\") .append(\"middleName:\").append(middleName).append(\"\\n\") .append(\"lastName:\").append(lastName); return sb.toString(); } public static void main(String[] args) throws Exception { TransientExample e = new TransientExample(\"Adeline\",\"test\",\"Pan\"); ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(\"/path/testObj\")); oos.writeObject(e); ObjectInputStream ois = new ObjectInputStream(new FileInputStream(\"/path/testObj\")); TransientExample e1 = (TransientExample) ois.readObject(); System.out.println(\"e:\"+e.toString()); System.out.println(\"e1:\"+e1.toString()); } }
View Code
输出结果:
e:firstName:Adeline middleName:test lastName:Pan
e1:firstName:Adeline middleName:null lastName:Pan
被transient关键字修饰的middleName字段没有被序列化,反序列化回来的值是null
Q:HashMap类是实现了Serializable接口的,那么为何其中的table, entrySet变量都标为transient呢?
A:我们知道,table数组中元素分布的下标位置是根据元素中key的hash进行散列运算得到的,而hash运算是native的,不同平台得到的结果可能是不相同的。举一个简单的例子,假设我们在目前的平台有键值对 key1-value1,计算出key1的hash为1, 计算后存在table数组中下标为1的地方,假设table被序列化了,并传输到了另外的平台,并反序列化为了原来的HashMap,key1-value1仍然存在下标1的位置,当在这个平台运行get(\"key1\")的时候,可能计算出key1的hash为2,就有可能到下标为2的地方去找该元素,这样就出错了。
Q:那么HashMap是如何实现的序列化呢?
A:HashMap是通过实现如下方法直接将元素数量(size), key, value等写入到了ObjectOutputStream中,实现的定制化的序列化和反序列化。在Serializable接口中有关于这种做法的说明。
private void writeObject(java.io.ObjectOutputStream out) throws IOException private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
HashMap, HashTable, ConcurrentHashMap 对照

这里只记录主要的不同点, 实现细节的不同忽略。
1. HashMap允许key 和 value为null, key为null的元素会存储在数组下标为0的位置,HashTable 中key和value都不允许为null, 否则会抛NPE
2. HashTable中put, get, remove等方法都使用synchronized关键字修饰, 也就是HashTable是线程安全的,HashMap不是线程安全的
3. HashTable是在方法级别做的线程同步, 虽然线程安全,但是对性能的影响较大。ConcurrentHashMap进行了优化, 下面结合多线程下可能产生冲突的地方分析ConcurrentHashMap的不同之处:
1)在put或者remove元素时,这个元素映射到的table数组下标处的链表/红黑树, 如果有其他线程同时操作这个链表/红黑树则可能造成混乱。所以冲突的资源是table数组中某一个需要被操作的下标处,所以操作时只要锁住这个下标处第一个Node节点即可。
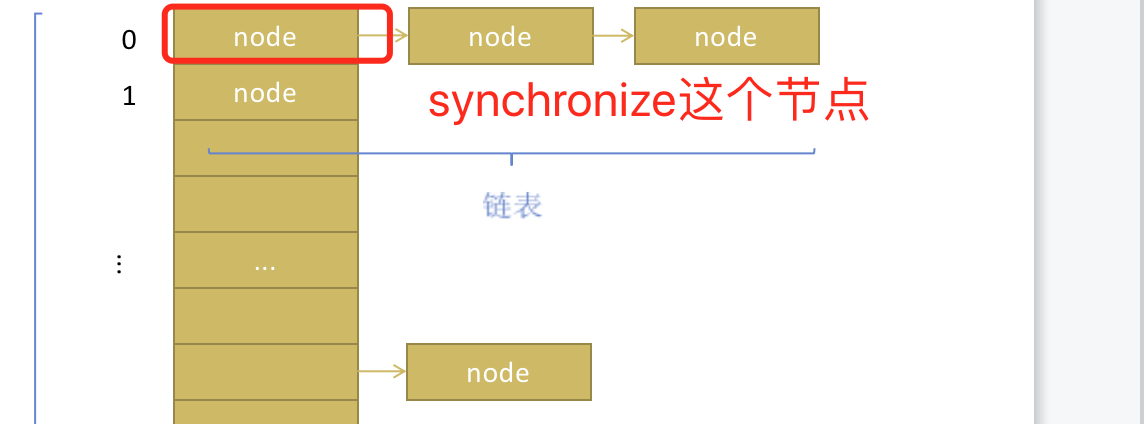
2)对于何时resize和如何resize。在多线程情况下,不能用一个简单的size是否到达阈值来判断是否需要resize,这样很有可能造成两个线程同时进行resize而造成混乱。我查看了一下ConcurrentHashMap的源代码,果然没有看到size这个变量了,put操作的最后,也不是简单的进行++size>threshold来判断是否进行resize了,而是一个新的addCount方法,目前还没太看懂。
3)在一个线程A进行get(key)操作时,可能有另外的线程B也正在操作这个key,比如可能修改,或者删除。那么线程B的操作结果在写回主存之前是对线程A不可见的,也就是线程A可能会读到一个已经无效的数据。但是get方法中并没有synchronized关键字,此处是使用的volatile来保证的, 下一小节再多说一点volatile关键字。
关于volatile关键字
volatile关键字的作用
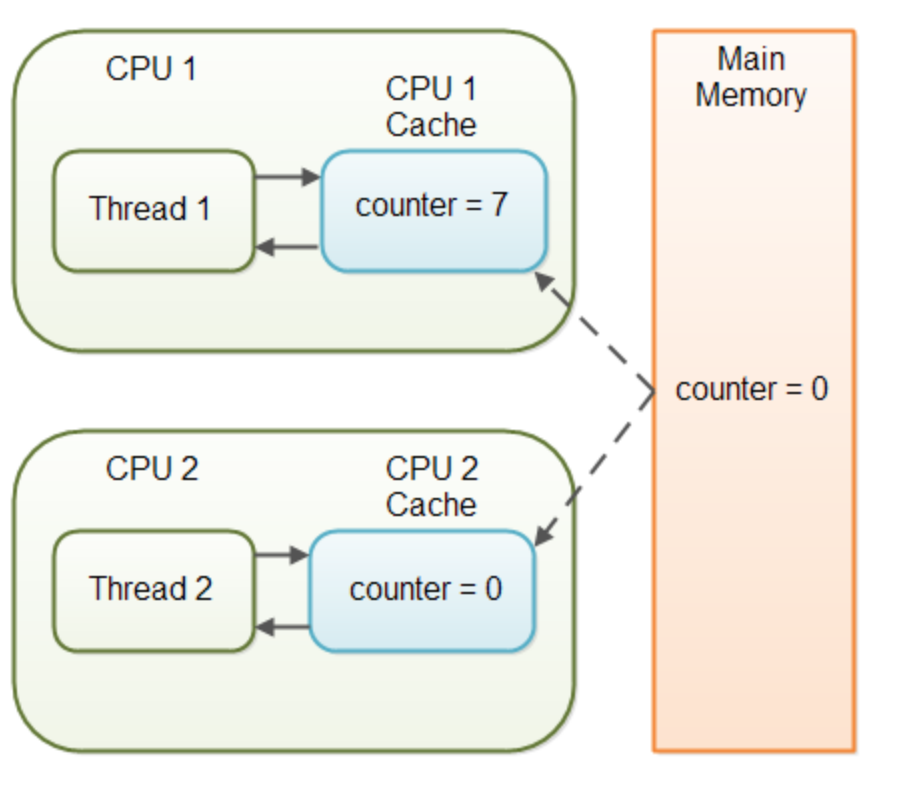
volatile关键字是保证共享变量在一个线程中的修改, 在其他线程中可见。我们知道Java运行过程中,会把变量从主内存中拷贝到各自的工作内存中(cpu cache),可能会对变量进行改变,操作完后会把改变后的值再写会到主存。如果两个线程同时读取主存的某个变量,其中一个线程对变量进行了修改,那么这个修改可能对另一个线程不可见。如下图(这个懒得画了,Google的图): Thread 1 和Thread 2同时从主存中读取了counter = 0, 然后Thread1将其改为了7,那么这个修改Thread2是不知道的,还当counter = 0。如果counter这个变量是用volatile修饰就可以避免这种情况。
如下面的例子:
public class VolatileExample1 { private static volatile int[] num = new int[] {1,1}; public static void main(String[] args) throws InterruptedException { new Thread(() -> { System.out.println(\"Thread 1 starts to sleep 1s\"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } num[0] = 0; System.out.println(\"Thread 1 finished and changed values\"); }).start(); while(true) { if(num[0] == 0) { System.out.println(\"see the change, main thread ends\"); break; } } } }
如狗num变量用volatile修饰, 则结果如下:
Thread 1 starts to sleep 1s Thread 1 finished and changed values see the change, main thread ends
主线程可以看到num[0]被修改成了0, 可以退出
如果去掉volatile,输出只有前两句,主线程迟迟观察不到数据的修改,没有退出。
ConcurrentHashMap(CHM)中使用volatile
接上一小节,get方法中没有使用synchronized关键字,那是如果保证get的时候对于其他线程可能的修改的可见性的呢?我们在源码中使用了volatile关键字
下面截取部分代码:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; ... } /* ---------------- Fields -------------- */ /** * The array of bins. Lazily initialized upon first insertion. * Size is always a power of two. Accessed directly by iterators. */ transient volatile Node<K,V>[] table; /** * The next table to use; non-null only while resizing. */ private transient volatile Node<K,V>[] nextTable; ...
可以看到table数组,和数组中的Node节点里面的元素都声明为了volatile.
1) table数组的volatile是保证在resize的时候,由于要重新创建一个数组,操作好后将table指向新数组,所以此处是保证在多线程的情况下,线程对于table指向的内存地址的修改对于其他线程是可见的
2)因为对于数组声明的volatile只保证数组指向的内存地址的可见性,所以数组里面的Node节点中的变量也声明了volatile,保证节点内容变化的可见性。
3)还要说明一点,大部分的系统(JVM)实现都是在读一个volatile变量的时候,会把其他线程所做的所有的修改(包括其他变量)都写回主存。所以我们在自己做实验的时候,如果只把某个对象的数组声明为volatile,而其中的Object里面的变量都不是volatile,然后在线程A里面修改Object里面的值,我们会发现在线程B里面也能看到修改的(并不是预想看不到修改)。 但是我猜测此处是为了确保正确,CHM将Node类中的变量也声明为volatile.
来源:https://www.cnblogs.com/adeline-tech/p/16666235.html
本站部分图文来源于网络,如有侵权请联系删除。