 百木园
百木园Beats 是轻量级(资源高效,无依赖性,小型)和开放源代码日志发送程序的集合,这些日志发送程序充当安装在基础结构中不同服务器上的代理,用于收集日志或指标;本文主要介绍 Beats 的理论内容。
1、Beats 是什么
在集中式日志记录中,数据管道包括三个主要阶段:聚合,处理和存储。 在 ELK 堆栈中,传统上,前两个阶段是堆栈工作量 Logstash 的职责。执行这些任务需要付出一定的代价。 由于与 Logstash 的设计有关的内在问题,性能问题变得经常发生,尤其是在复杂的管道需要大量处理的情况下。将 Logstash 的部分职责外包的想法也应运而生,尤其是将数据提取任务转移到其他工具上。 正如我在本文中所描述的,这个想法首先在 Lumberjack 中体现出来,然后在 Logstash 转发器中体现出来。 最终,在随后的几个开发周期中,引入了新的改进协议,该协议成为现在所谓的 “Beats” 家族的骨干。
Beats 是轻量级(资源高效,无依赖性,小型)和开放源代码日志发送程序的集合,这些日志发送程序充当安装在基础结构中不同服务器上的代理,用于收集日志或指标(metrics)。这些可以是日志文件(Filebeat),网络数据(Packetbeat),服务器指标(Metricbeat)或 Elastic 和社区开发的越来越多的 Beats 可以收集的任何其他类型的数据。 收集后,数据将直接发送到 Elasticsearch 或 Logstash 中进行其他处理。Beats 建立在名为 libbeat 的 Go 框架之上,该框架用于数据转发,这意味着社区一直在开发和贡献新的 Beats。
2、Elastic Beats
Elastic Stack 提供了一些常用的 Beats:

2.1、Filebeat
顾名思义,Filebeat 用于收集和传送日志文件,它也是最常用的 Beat。 Filebeat 如此高效的事实之一就是它处理背压的方式 -- 因此,如果它连接的 Logstash 处于繁忙状态,Filebeat 会减慢其读取速率,并在减速结束后加快节奏。Filebeat 几乎可以安装在任何操作系统上,包括作为 Docker 容器安装,还随附用于特定平台(例如 Apache,MySQL,Docker等)的内部模块,其中包含这些平台的默认配置和 Kibana 对象。
2.2、Packetbeat
网络数据包分析器 Packetbeat 是第一个引入的 Beat。 Packetbeat 捕获服务器之间的网络流量,因此可用于应用程序和性能监视。Packetbeat 可以安装在受监视的服务器上,也可以安装在其专用服务器上。 Packetbeat 跟踪网络流量,解码协议并记录每笔交易的数据。 Packetbeat 支持的协议及中间件包括:DNS,HTTP,ICMP,Redis,MySQL,MongoDB,Cassandra 等。
2.3、Metricbeat
Metricbeat 是一种非常受欢迎的 beat,它收集并报告各种系统和平台的各种系统级指标。 Metricbeat 还支持用于从特定平台的内部模块收集统计信息。你可以使用这些模块和称为指标集的 metricsets 来配置 Metricbeat 收集指标的频率以及要收集哪些特定指标。
2.4、Heartbeat
Heartbeat 是用于 “uptime monitoring” 的。本质上,Heartbeat 是探测服务以检查它们是否可访问。 你要做的就是为 Heartbeat 提供 URL 和正常运行指标的列表,检测结果可以发送到 Elasticsearch 或 Logstash 以进行进一步分析。
2.5、Auditbeat
Auditbeat 可用于审核 Linux 服务器上的用户和进程活动。 与其他传统的系统审核工具(systemd,auditd)类似,Auditbeat 可用于识别安全漏洞-文件更改,配置更改,恶意行为等。
2.6、Winlogbeat
Winlogbeat 仅会引起 Windows 系统管理员或工程师的兴趣,因为它是专门为收集 Windows 事件日志而设计的 Beat。 它可用于分析安全事件,已安装的更新等。
2.7、Functionbeat
Functionbeat 被定义为 “serverless” 的发件人,可以将其部署为收集数据并将其发送到 ELK 堆栈的功能。 Functionbeat 专为监视云环境而设计,目前已针对 Amazon 设置量身定制,可以部署为 Amazon Lambda 函数,以从 Amazon CloudWatch,Kinesis 和 SQS 收集数据。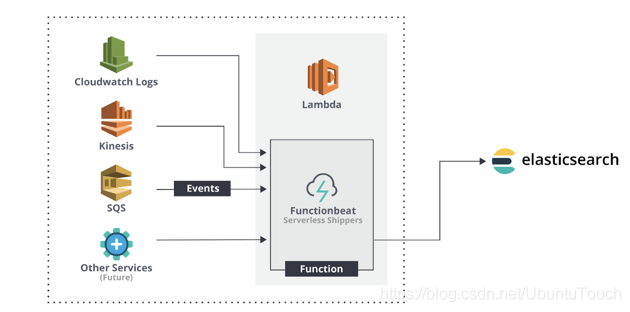
3、社区 Beats
开源社区一直在努力开发新的 Beats。对社区 Beats 有疑问吗? 你可以在 Beat 讨论论坛的 Community Beats 类别中发布问题并讨论问题。目前有超过90个 Beats。如果大家有发现有用的 Beat,你可以直接下载并使用。
4、Beats 在 Elastic 堆栈中是如何融入的
到目前为止,有如下的三种方式能够把我们所感兴趣的数据导入到 Elasticsearch 中:

正如上面所显示的那样,我们可以通过:
- Beats:我们可以通过 Beats 把数据直接导入到 Elasticsearch 中。
- Logstash:我们可以通过 Logstash 把数据导入。Logstash 的数据来源也可以是 Beats。
- REST API:我们可以通过 Elastic 所提供的丰富的 API 来把数据导入到 Elasticsearch中。我们可以通过 Java, Python, Go, Nodejs 等各种 Elasticsearch API 来完成我们的数据导入。
那么针对 Beats 来说,Beats 是如何和其它的 Elastic Stack 一起工作的呢?我们可以看如下的框图:
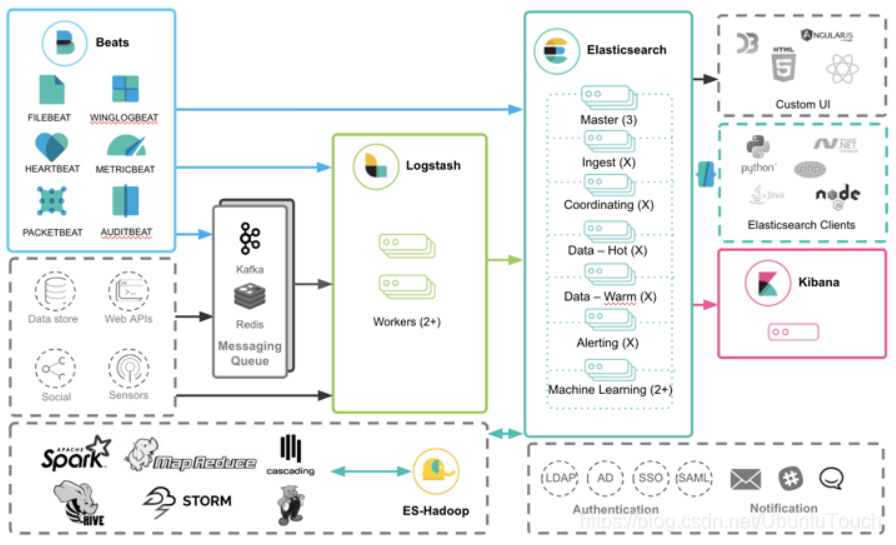
从上面我们可以看出来,Beats 的数据可以有如下的三种方式导入到 Elasticsearch 中:
- Beats ==> Elasticsearch
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
正如上面所显示的那样:
- 我们可以直接把 Beats 的数据传入到 Elasticsearch 中,甚至在现在的很多情况中,这也是一种比较受欢迎的一种方案。它甚至可以结合 Elasticsearch 所提供的 pipeline 一起完成更为强大的组合。
- 我们可以利用 Logstash 所提供的强大的 filter 组合对数据流进行处理:解析,丰富,转换,删除,添加等等。
- 针对有些情况,如果我们的数据流具有不确定性,比如可能在某个时刻生产大量的数据,从而导致 Logstash 不能及时处理,我们可以通过 Kafka 或者 Redis 做为 Messaging Queue 来做一个缓存。
5、摄入管道(ingest pipeline)
我们知道在 Elasticsearch 的节点中,有一类节点是 ingest node。ingest pipeline 运行于 ingest node 之上。
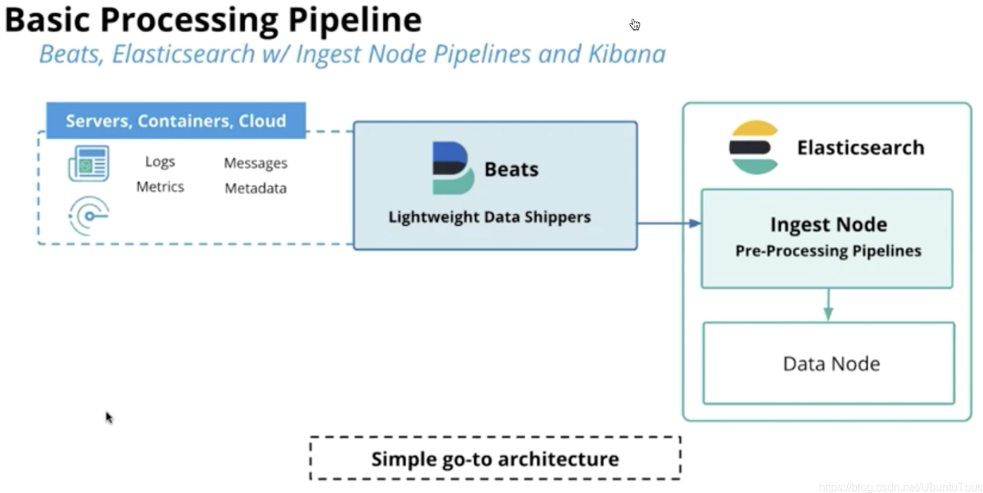
它提供了在对文档建立索引之前对其进行预处理的功能:
- 解析,转换并丰富数据
- 管道允许你配置将要使用的处理器
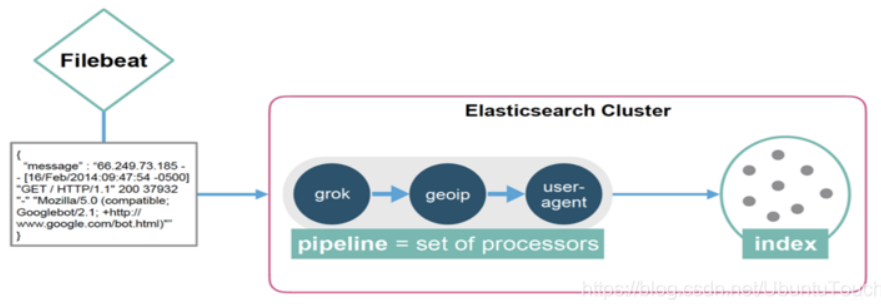
在上面的图中,我们可以看出来,我们可以使用在 Elasticsearch 集群里的 ingest node 来运行我们所定义的 processors;可以查看官方文档 Processors 来详细了解 processor。
6、Libeat - 创建 Beats 的 Go 架构
Libbeat 是一个用于数据转发的库。Beats 构建在名为 libbeat 的 Go 框架之上。 它是一个开源的软件。我们可以在地址 https://github.com/elastic/beats/tree/master/libbeat 找到它的源码。它可以轻松地为你想要发送到 Elasticsearch 的任何类型的数据创建自定义 Beat。
对于一个 beat 来说,它可以分为如下的两个部分:数据收集器,数据处理器及发布器。后面的这个部分由 libbeat 来提供。
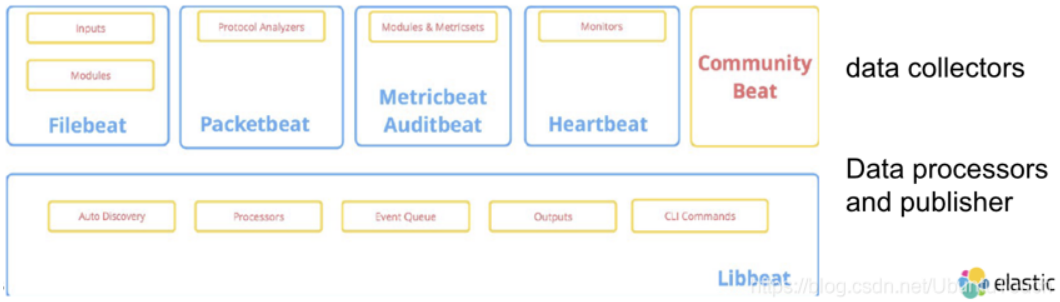
可以查看官网 Define processors 来了解 processor 的详细信息,processor 的一些例子:
- add_cloud_metadata - add_locale - decode_json_fields - add_fields - drop_event - drop_fields - include_fields - add_kubernetes_metadata - add_docker_metadata
参考:https://blog.csdn.net/UbuntuTouch/article/details/104432643
来源:https://www.cnblogs.com/wuyongyin/p/16696635.html
本站部分图文来源于网络,如有侵权请联系删除。