 百木园
百木园我的博客
在写python脚本的时候,例如,我写一个test1.py
def test(n): print(n) if __name__ == \'__main__\': n = 1 test(1)
接下来打开cmd命令窗口,执行命令
python test.py
结果是把1打印出来
这时候就会有同学有疑问了,我直接写不行么,在test1.py的同一个目录下创建test2.py
def test(n): print(n) n = 1 test(1)
这时候尝试执行test2.py,执行结果是一样的,那我干嘛非要多浪费一行代码写那玩意呢
其实python有个特性,就是这个文件是可以通过import在另一个python脚本中引用的,现在,在test1.py的同一个目录下加一个空文件的__init__.py,其实不加也行,系统会自动生成
然后在修改下test1.py这个文件
import test2 #增加这行,引用刚刚的test2 def test(n): print(n) if __name__ == \'__main__\': n = 1 # test(1) 把这行注释掉,不执行 test2.test(n)
执行python test1.py测试下

这里会打印出两个1,是不是很奇怪,按理说应该和直接执行test2时候是一样的,打印一个1啊,这就不得不说到__name__这个系统变量了,现在把test2.py改一下
def test(n): print(n) print(\'__name__ is: \' + __name__) #把__name__的信息打印出来 n = 1 test(1)
再次执行test1.py
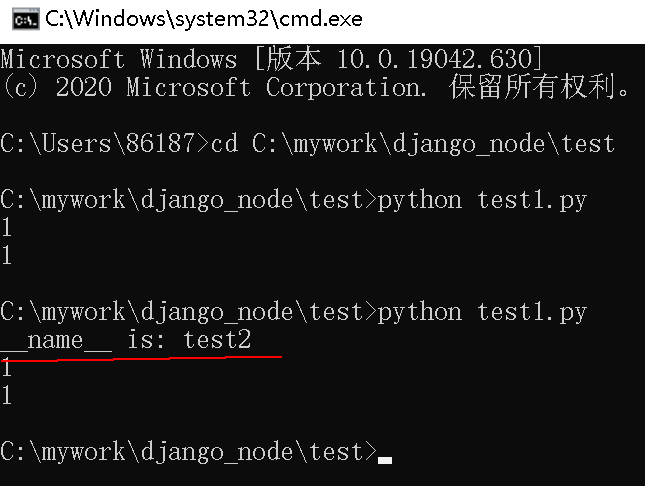
看到没,在引用的时候__name__变量是test2,就是引用的文件名,所以if __name__ == \'__main__\'是False,不会执行
现在直接执行test2.py

看到了吧,直接执行test2.py的时候__name__变量是__main__,那么if __name__ == \'__main__\'就成了True,会执行
也就是说if __name__ == \'__main__\'加上这句实际上是为了避免调用的时候错误的把测试的内容执行了,现在再改下test2.py
def test(n): print(n) # 加上if __name__ == \'__main__\' if __name__ == \'__main__\': print(\'__name__ is: \' + __name__) #把__name__的信息打印出来 n = 1 test(1)
再次执行test1.py,现在的执行结果就是期望的一个1的结果啦
来源:https://www.cnblogs.com/xiu123/p/16767493.html
本站部分图文来源于网络,如有侵权请联系删除。