 百木园
百木园
哈喽大家好,我是策略产品经理Arthur,目前在某头部互联网公司任职广告策略产品专家。分享完推荐系统排序那些事儿,今天我们继续介绍召回的那些事儿。那篇文章发表之后有很多朋友在评论区,希望我详细拆讲一下各个模块的策略,话不多说我们直接上肝货。
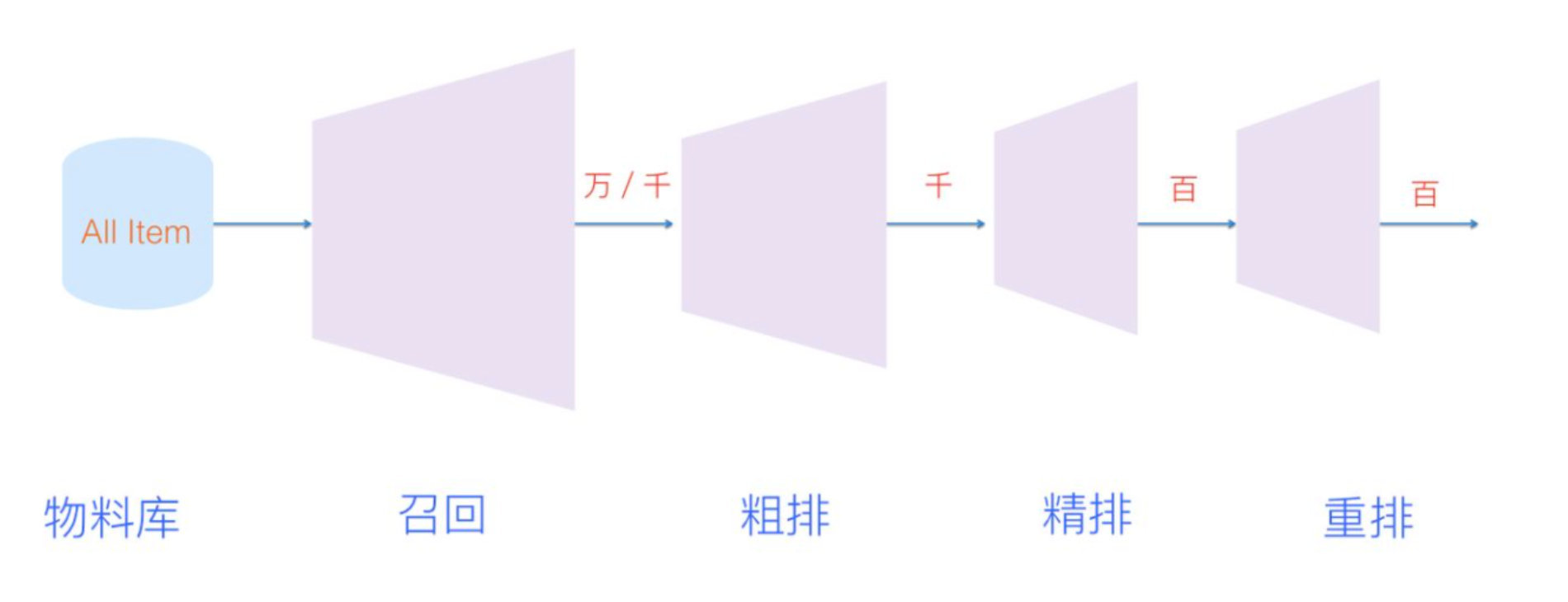
那么应大家的需求过来抛砖引玉给大家讲讲推荐系统的召回,帮助各位对推荐策略产品感兴趣的同学建立一下基础认知;我将分为三个部分来介绍:
一、什么是召回,召回具体在做一件什么样的事儿

召回Matching从整体思路与作用上是完全与排序对立区分开的存在,指的是从全量的信息item集合中出发尽可能多的正确结果,通过对大而全的输入集合输入到排序模块进行顺序排序,为排序提供候选集合。
- 召回特点:保证相关集合的量大、处理的速度要够快,并且模型使用比较简单,特征选取比较少。
- 排序特点:物料集合精炼、那么特征就会要求复杂,模型也会复杂,最终呈现的结果需要准,抓住用户兴趣点;
推荐系统中的召回面对的是全量信息池,需要从整个信息集合中挑选出尽可能多的相关结果,剔除相关性较弱的结果,降低排序阶段的工作量。
二、目前工业界有哪几种主流召回方式
目前工业界推荐系统的主流召回方式包含三种分类:基于规则标签类召回、协同过滤召回方式、模型向量召回的方式。
在介绍每一种召回方式之前,大家要厘清一个概念,一般推荐系统的搭建不会是单一维度的召回,因为所面临的业务场景复杂(需要考虑无数据冷启动状态、考虑用户与物料之间的状态、物料与物料的状态),一般是多类型的召回方式协同,最终进行多路归一化进行并存,这个就叫做多路召回,核心是为了避免召回结果单一规则束缚,使得与推荐系统内容丰富性效果相违背。
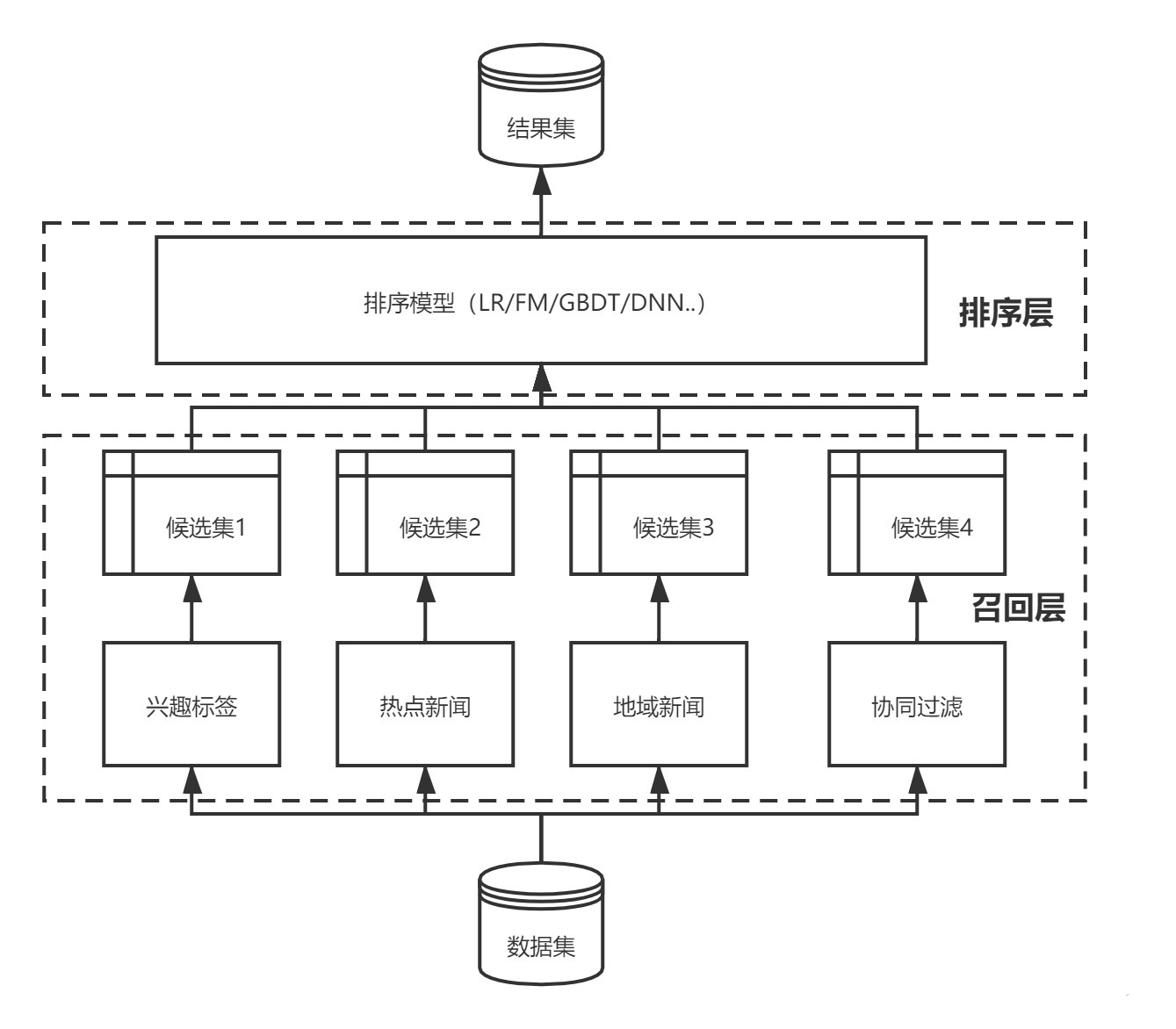
2.1 基于规则、标签类的召回
与其说是一种常规的召回方式,不如说是一种运营规则配置规则,可解读性最好的召回方式,一般逻辑清晰明了,基于推荐系统的业务目标进行简单的规则召回,这里拿抖音举例子。
热门规则召回:
比如近 7 天完整播放率比较高的短视频,可以结合互动点击率CTR 和时间戳衰减,例如30天、7天做平滑的视频物料,这部分主要基于数据统计规则实现并进行展现即可,例如垫底辣孩的国风少年系列、超模系列。
但是由于热门 item召回和推荐过多其实容易导致视频马太效应,这其实不利于其他用户的视频召回展现,从而破坏了抖音短视频的丰富多态。如果热门召回占整体通路比例过大,可以考虑做一定打压,也就是在前面的权重当中降低权重系数(例如从0.5降低到0.3)。
运营标签、召回:
例如运营构建的各个类目的PCG时效榜单,例如国风美少年、光剑变装榜单召回,还有就是时下热点新闻,例如冬奥会谷爱凌视频等,这种大家喜闻乐见的视频,但是一定要注意对于时间戳的控制。
比如已经到了夏天还召回大量冬奥会谷爱凌夺冠的视频,这样就不合适了,毕竟新闻注重的就是时效性。
2.2 协同过滤召回
协同过滤(collaborative filtering)是一种在推荐系统中广泛使用的技术,最早诞生与1992年,该技术通过分析用户和用户之间或者用户和是事物之间的相似性(“协同”),通过互斥相差异的性质排除掉相斥的物料和用户(“过滤”),来预测用户可能感兴趣的物料内容并将此内容推荐给用户,核心分成两大类,一大类基于用户相似性召回的方式叫做User-CF即用户协同过滤,一种基于物料item相似性召回的方式即Item-CF物料协同过滤;
2.2.1 基于用户的协同过滤User-CF ;
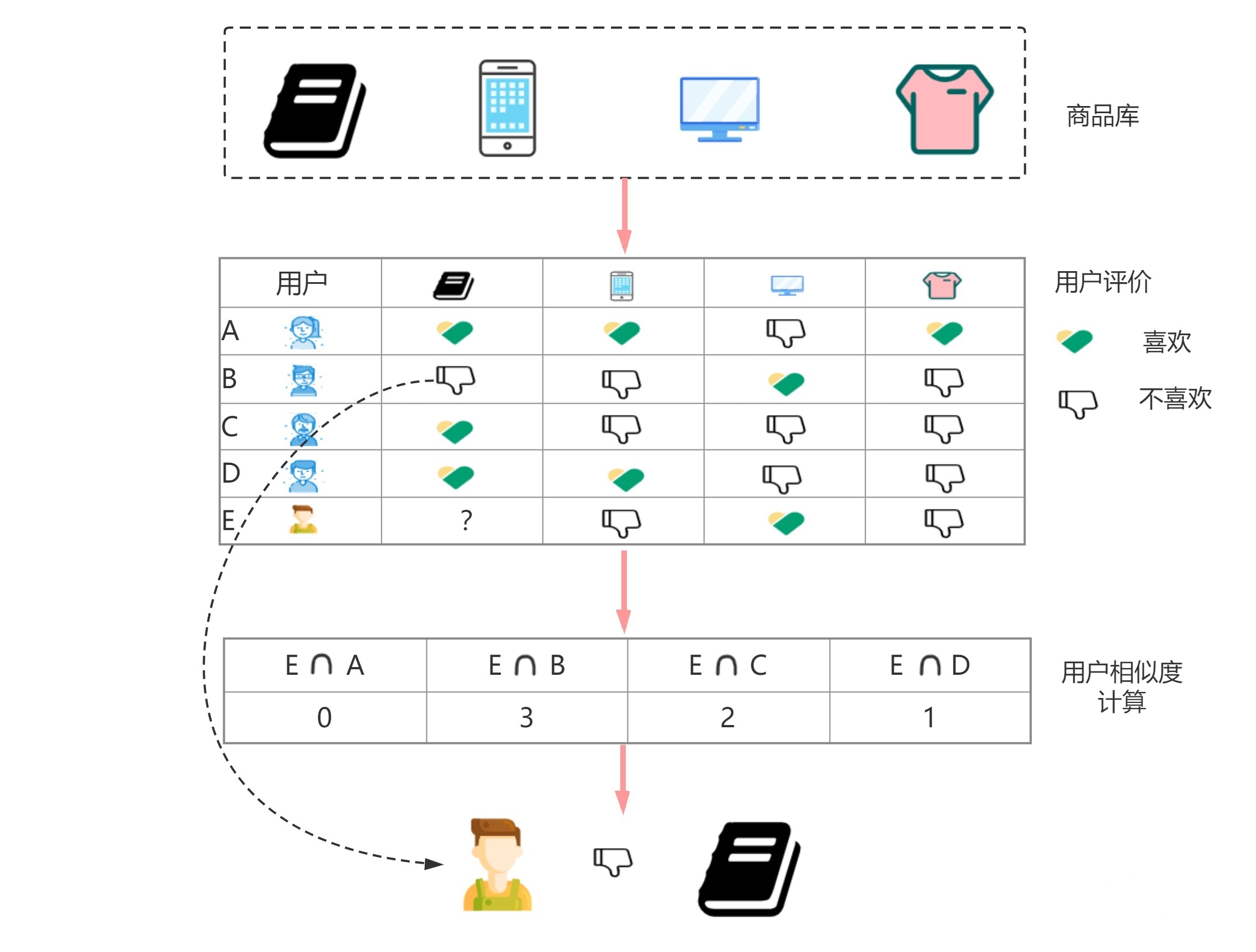
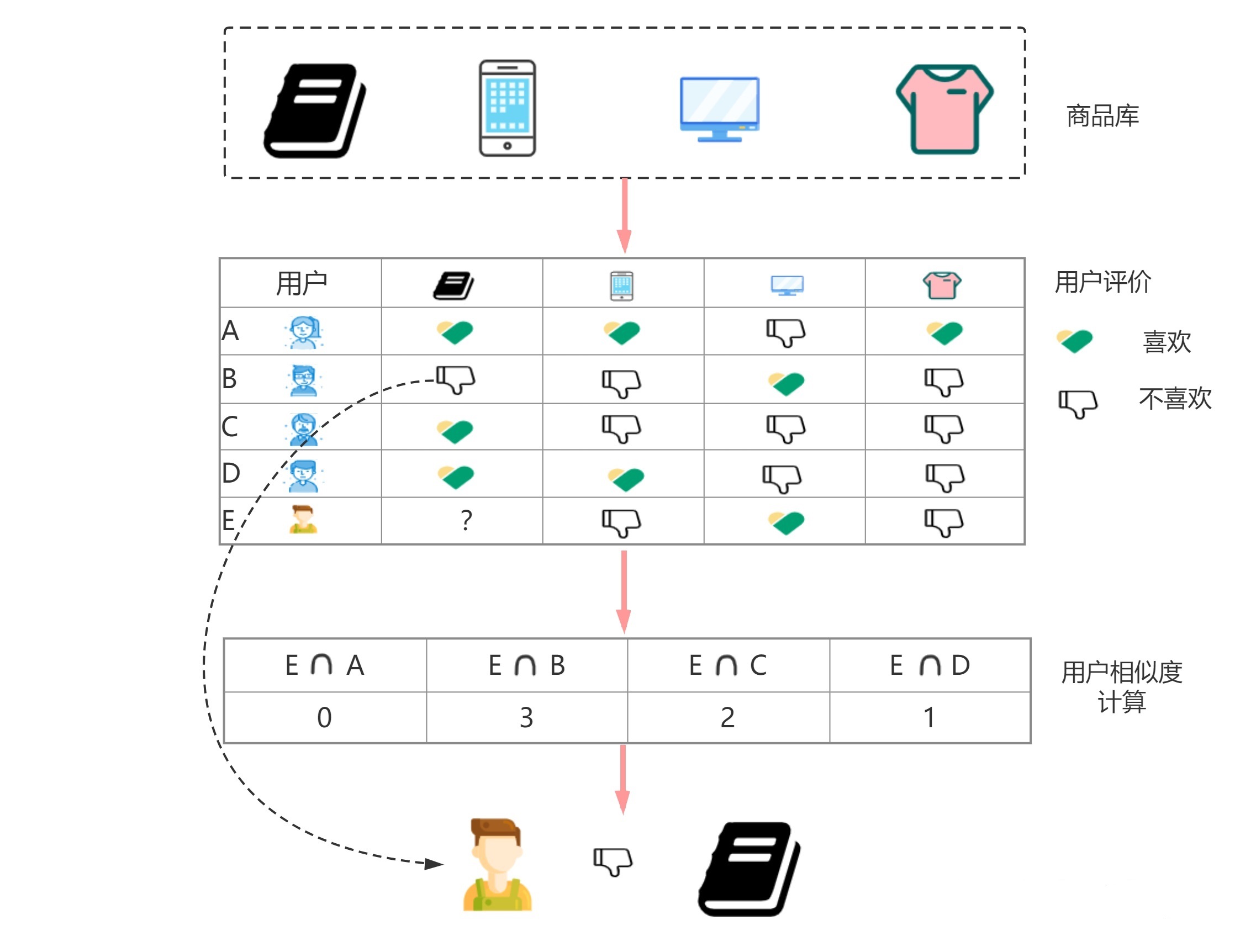
给大家举个例子,用户A、B、C、D在电商平台对商品书本、计算器、显示器和衣服表达了自己的评价爱好,喜欢用1,无感用0,不喜欢用-1,纵左边为用户编号,横坐标为商品类型,基于上述用户反馈表现,我们构建出共现矩阵如下:
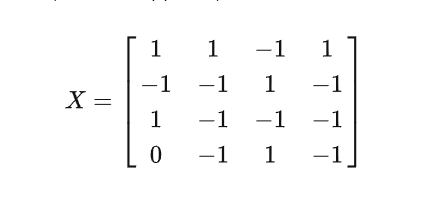
计算用户E和其他的用户之间相似度,可以发现用户E对商品兴趣的行向量为:
![]()
我就可以通过K邻近的方式选出相速度TopN的用户数,可以看出用户E对四个商品的偏好和B最相似,其次是C,那么接下来我将会把B、C感兴趣且没有对E进行曝光过的商品对E进行曝光,以上的逻辑其实就是User-CF的大体思路;对于User-CF计算用户之间相似度的方法有很多,有Jaccard距离、余弦相似度、欧式距离等多种。

在得到最终的TopN个用户之后,还需要对用户的评分做加权平均,计算用户用户之间相似度,以及用户i对p的评分,最终算出用户E对B、C关联的商品兴趣度,得到的排序靠前的结果即可进行召回。
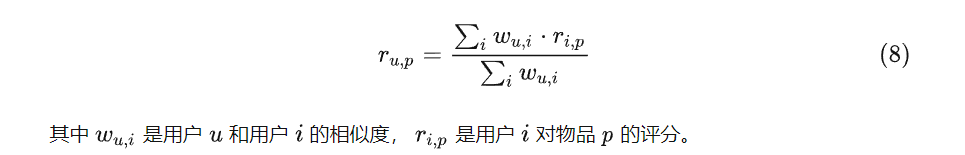
2.2.2 基于物料的协同过滤Item-CF
最早是Amazon在2001年提出的理念,核心思想是基于物料之间的相似度,来构建两两物品之间的相似度矩阵,这个地方的相似度不是指代的分类与标签这种类型(如何是简单的标签就是变成前文提到的规则类召回了),而是通过多个用户对商品之间行为的相似性,来构建物料Item相似性的关系,这是Item-CF的核心思想。
这里再拿上面的内容举个例子,书本和手机被A、B、C、D都连续评价了喜欢,而手机和显示器只被A、C、D 三位用户评价了喜欢,那么通过构建物品的相似度矩阵,通过用户的正向反馈行为,就可以得到书本和手机最为相似、其次手机和显示器也比较相似,通过这样的计算思路和理念,我们也可以构建一个相似的共现矩阵。
如果用户E来到了电商平台对手机给出了好评的话,那么我们认为E对于书本、显示器也会比较感兴趣,因为书本和手机、手机和显示器比较相似度高,Item-CF核心就是构建Item物料的相似度。
构建完成TopN个相似的物品,然后通过计算物品和用户历史浏览评分的加权和得到最终的结果,对TopN个用户E可能感兴趣的商品召回回来。

总体来看,协同过滤就是通过物体与用户之间相似度关系来构建共现矩阵,然后通过距离、相似度计算的方法来构建出用户可能的兴趣点再来进行召回,详细的应用场景可以见文章结尾。
2.3 向量Embedding召回方式
向量embedding其实就是用一个低维稠密的有方向有长度的线性表示一个对象,也就是通过数学的方式来代表一个对象,这里的对象可以是一个词、一个商品,也可以是一篇新闻、一部电影,等等。
如果一本英语词典有10万个单词,那么表示十万个维度,我们转化成为低维度的稠密向量,这样就可以计算词之间的相似度了,这个模型就是embedding产生的过程,这就是word2 Vec的基本思路。经过向量化之后发现man 和 woman 这两个单词通过欧式距离计算是距离最近的,我们就可以理解为四个单词是最相近的。

同样的道理放在召回上也是一样,我们把物料和用户构建向量相似性拆分开就可以得到,在推荐系统中比较典型的几种召回方式像是i2i(item2item)召回(有Graph Embedding的i2i召回、内容语义的i2i召回)、对于u2i召回(即user2item召回方式)有经典的DSSM双塔召回、还有Youtube深度学习召回方法,在这里给大家举例DSSM双塔召回,这个是2013年微软研究发表的一篇论文。

DSSM双塔结构,两遍分别输入user特征(各种复杂特征画像:消费能力、标签喜好、在线行为等等)和广告ad特征(新闻广告投放的item词特征、图片特征以及词特征等等),经过DNN变化之后分别产出user和ad向量Embedding。
DSSM的user和ad侧是两个独立的自网络,离线产出user embedding和ad embedding 后存储在redis数据库中,在召回的时候去计算两者的余弦相似度相似度/Jaccard系数或者是欧式距离选取K邻近的TopN个广告单元id,为访问用户选择兴趣度最高的广告类型,降低用户对广告的排斥心理,这样就完成了广告推荐任务。
这里给大家推荐一下Airbnb在18年8月在KDD发表的基于用户短期兴趣和长期兴趣的Embedding召回方式,基于实际业务和数据的特点,Airbnb搭建了基于短期兴趣房源Embedding和基于长期兴趣的房源Embedding,效果非常好,大家感兴趣可以去了解一下。
三、关于对召回的总结
最后和大家做一下总结,其实上述多种召回方式都会在一个推荐系统并存,每种召回方式都有其特点和使用场景,最终在召回汇的时候多路召回权重归一化;每种召回都有特定的场景来使用。
规则类召回:更多的使用在用户在未产生数据冷启动阶段(无标签、无行为数据,模型巧妇难为无米之炊),通过规则选出TopN来让用产生一些列的平台,积累用户行为数据,这种召回方式的特点是可解释性强,但是个性化能力不足,马太效应聚集明显。
协同过滤类型:
- 基于用户协同过滤User-CF:在新闻等流媒体平台使用较多,通过用户之间的的相似性,来推荐未看过的新闻内容,这种社交网络显示用户推荐来源,可以增加推荐内容的信服度;
- 基于物料的协同过滤Item-CF:在电商平台使用较多,因为在电商平台上物品的数据稳定性更强不会随时更换,计算物品相似度相对来说计算复杂度更低一点;
双塔模型DSSM向量Embedding召回:相对来说应用场景就非常广了,无论是广告、自然推荐系统当中都广泛应用,读取和计算速度很,个性化能力较强推荐效果较好,缺点就是可解释性较差,交叉特征缺失,整体交叉特征发挥的效果优势比较少。
本文由 @策略产品Arthur 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
来源:https://www.woshipm.com/operate/5652602.html
本站部分图文来源于网络,如有侵权请联系删除。