 百木园
百木园Python正则表达式
目录
- Python正则表达式
- 快速参考
- 函数详解
- match()
- search()
- 捕获和分组
- Match对象
- sub()
- compile()
- findall()
- finditer()
- split()
- 参考博客与示例代码
快速参考
常用函数:
re.match():从字符串的起始位置匹配一个正则表达式。
re.search():扫描整个字符串并返回第一个成功的匹配。
re.sub():用于替换字符串中的匹配项。
re.compile():用于编译正则表达式,生成一个正则表达式(Pattern)对象。供match()和search()这两个函数使用。
re.findAll():在字符串中找到正则表达式所匹配的所有子串,并返回一个列表。
re.finditer():在字符串中找到正则表达式所匹配的所有子串,并返回一个迭代器。
re.split():split 方法按照能够匹配的子串将字符串分割后返回列表。
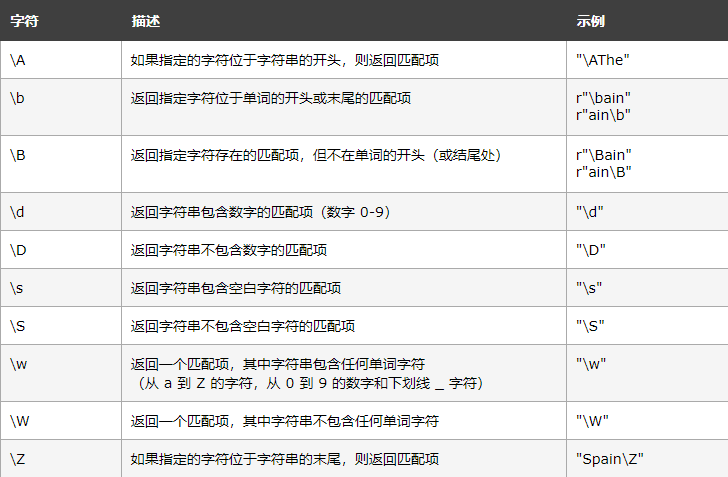
元字符:具有特殊含义的字符

特殊序列:特殊序列指的是\\后跟下表中的某个字符,拥有特殊含义。
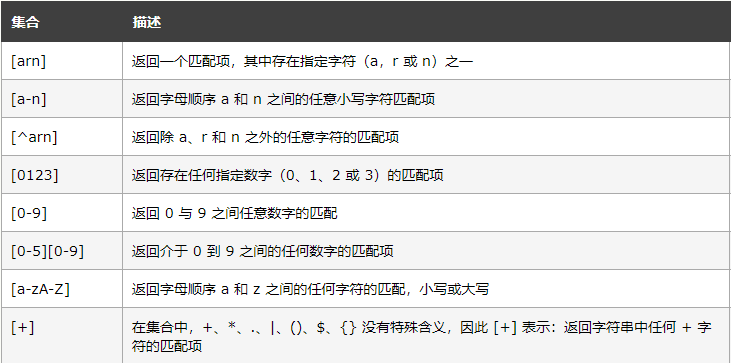
集合:集合(Set)是一对方括号 [] 内的一组字符,具有特殊含义
正则表达式修饰符

函数详解
match()
re.match(): 从字符串的起始位置(开头)匹配一个正则表达式,匹配成功返回一个Match对象,匹配失败返回None。
re.match(pattern, string, flags=0)
# pattern:正则表达式;string:字符串;flags:正则表达式修饰符
示例:
_str = \'https://www.baidu.com/\'
print(re.match(\'https\', _str))
print(re.match(\'baidu\', _str))
结果图:
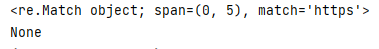
search()
re.search():扫描整个字符串来匹配正则表达式,如果匹配成功,则返回第一个匹配成功的Match对象,匹配失败则返回None。
re.search(pattern,string,flags=0)
# pattern:正则表达式;string:字符串;flags:正则表达式修饰符
示例:
_str = \'https://www.baidu.com/\'
print(re.search(\'baidu\', _str))
print(re.search(\'goole\', _str))
结果图:
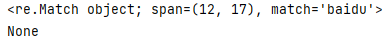
捕获和分组
示例:
_str = \'Cats are smarter than dogs\'
# r:字符串为非转义的原始字符串 ():捕获和分组 .:除了换行符的所有字符 *:零次或者多次出现
# (.*)是第一个分组,.*表示匹配除了换行符之外的所有字符;(.*?)是第二个分组,.*后面的?代表非贪婪模式,只匹配符合条件的最少的字符
# 最后一个.*不是分组,不会计入匹配结果;|表示两者任一
# re.M:多行匹配,影响^和$;re.I:大小写不敏感
# 匹配的正则表达式中的空格对结果影响很大
matchObject = re.match(r\'(.*) are (.*?) .*\', _str, re.M | re.I)
if matchObject:
print(matchObject.groups())
print(matchObject.group())
print(matchObject.group(1))
print(matchObject.group(2))
结果截图:

groups是包含分组匹配项的元组;group()或者group(0)是整个正则表达式的匹配项;group(1)和group(2)分别是两个分组的匹配项;当调用group(3)时会报错,因为没有第三个分组
Match对象
_str = \'https://www.baidu.com/\'
_result = re.match(\'https\', _str)
print(_result)
print(_result.span())
print(_result.start())
print(_result.end())
print(_result.group())

sub()
re.sub():用于替换字符串中正则表达式的匹配项。
re.sub(pattern, repl, string, count=0, flags=0)
# pattern:正则表达式;repl:替换的字符串或者函数;string:字符串;
# count:最大替换次数,默认0代表替换所有匹配正则表达式;flags:正则表达式修饰符
示例:
_phone = \'2004-959-559 # 这是一个国外电话号码\'
# 删除字符串中的Python注释
_phone = re.sub(r\'#.*$\', \'\', _phone)
print(_phone)
# 删除字符串中的-
_num = re.sub(r\'\\D\', \'\', _phone)
print(_num)
# 删除字符串中的-
_num = re.sub(r\'-\', \'\', _phone)
print(_num)
# 删除字符串中第一个-
_num = re.sub(r\'-\', \'\', _phone, 1)
print(_num)
结果图:

示例(repl参数是一个函数):
# 将字符串中的匹配的数字*2
def doubleNum(matched):
_value = int(matched.group(\'value\'))
return str(_value * 2)
_str = \'cxk666cxk456cxk250\'
# 分组匹配
_result = re.sub(r\'(?P<value>\\d+)\', doubleNum, _str)
print(_result)
结果图:
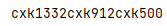
compile()
compile()函数用于编译正则表达式,生成一个正则表达式对象(RegexObject) ,供match()和search()这两个函数使用。
re.compile(pattern[, flags])
# pattern:正则表达式;flags:正则表达式修饰符
示例:
_str = \'cxk666cxk456cxk250\'
# re.compile函数,compile函数用于编译正则表达式,生成一个正则表达式对象
_pattern = re.compile(r\'\\d+\') # 匹配至少一个数字
_result = _pattern.search(_str)
print(_result)
结果图:

findall()
findall():在字符串中找到正则表达式所匹配的所有子字符串并返回一个列表。如果有多个匹配模式,则返回元祖列表;如果没有找到匹配子串,则返回空列表。
findall(string[, pos[, endpos]])
# string:字符串;pos:可选参数,字符串的起始位置,默认为0;endpos:可选参数,字符串的结束位置,默认为字符串长度。
示例:
_str = \'cxk666cxk456cxk250\'
_pattern = re.compile(r\'\\d+\') # 匹配至少一个数字
_result = _pattern.findall(_str)
print(_result)
结果图:

多个匹配模式示例:
_str = \'cxk666cxk456cxk250\'
_pattern = re.compile(r\'([a-z]+)(\\d+)\') #按小写字母和数字分开匹配
_result = _pattern.findall(_str)
print(_result)
结果图:
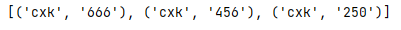
finditer()
finditer():在字符串中找到正则表达式所匹配的所有子串,并将结果作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
# string:字符串;pattern:正则表达式;flags:正则表达式修饰符
示例:
# finditer
_str = \'cxk666cxk456cxk250\'
_iter = re.finditer(r\'\\d+\', _str)
for _it in _iter:
print(_it.group())
结果图:

split()
split() 方法按照能够匹配的子串将字符串分割后返回列表。注意:是分割,而不是取某一部分。
re.split(pattern, string[, maxsplit=0, flags=0])
# pattern:正则表达式;string:字符串;maxsplit:分隔次数,默认为 0,不限制次数;flags:正则表达式修饰符
示例:
_str = \'cxk sing jump rap basketball\'
_result = re.split(r\'(\\S+ )\', _str)
print(_result)
结果图:

参考博客与示例代码
示例代码:https://gitee.com/mr-wildfire/PythonRegExDemo/
参考博客:
感谢:Python 正则表达式 | 菜鸟教程 (runoob.com)
感谢:Python RegEx (w3school.com.cn)
来源:https://www.cnblogs.com/wind-and-sky/p/16821295.html
本站部分图文来源于网络,如有侵权请联系删除。