 百木园
百木园目录
- 一、背景介绍
- 二、代码讲解
- 2.1 爬虫
- 2.2 tkinter界面
- 2.3 存日志
- 三、说明
一、背景介绍
你好,我是@马哥python说,一名10年程序猿。
最近我用python开发了一个GUI桌面软件,目的是爬取相关YouTube博主的各种信息,字段包括:
视频标题、视频链接、博主名称、博主链接、国家、telegram链接、whatsapp链接、twitter链接、facebook链接、instagram链接。
以近期某热门事件为例。
演示视频:
【爬虫演示】用python爬YouTube博主信息,并开发成GUI桌面软件!
运行截图:
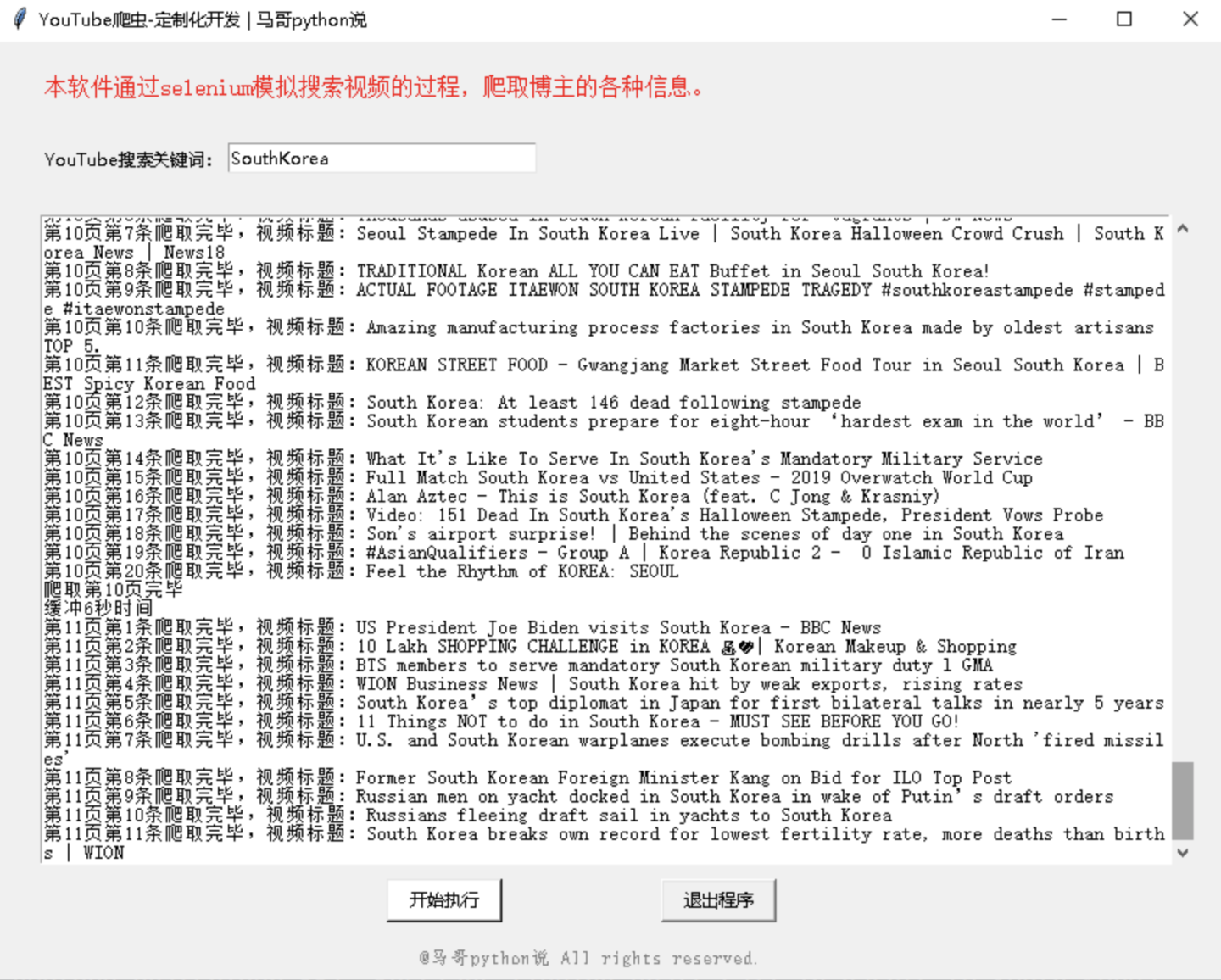
爬取数据截图:
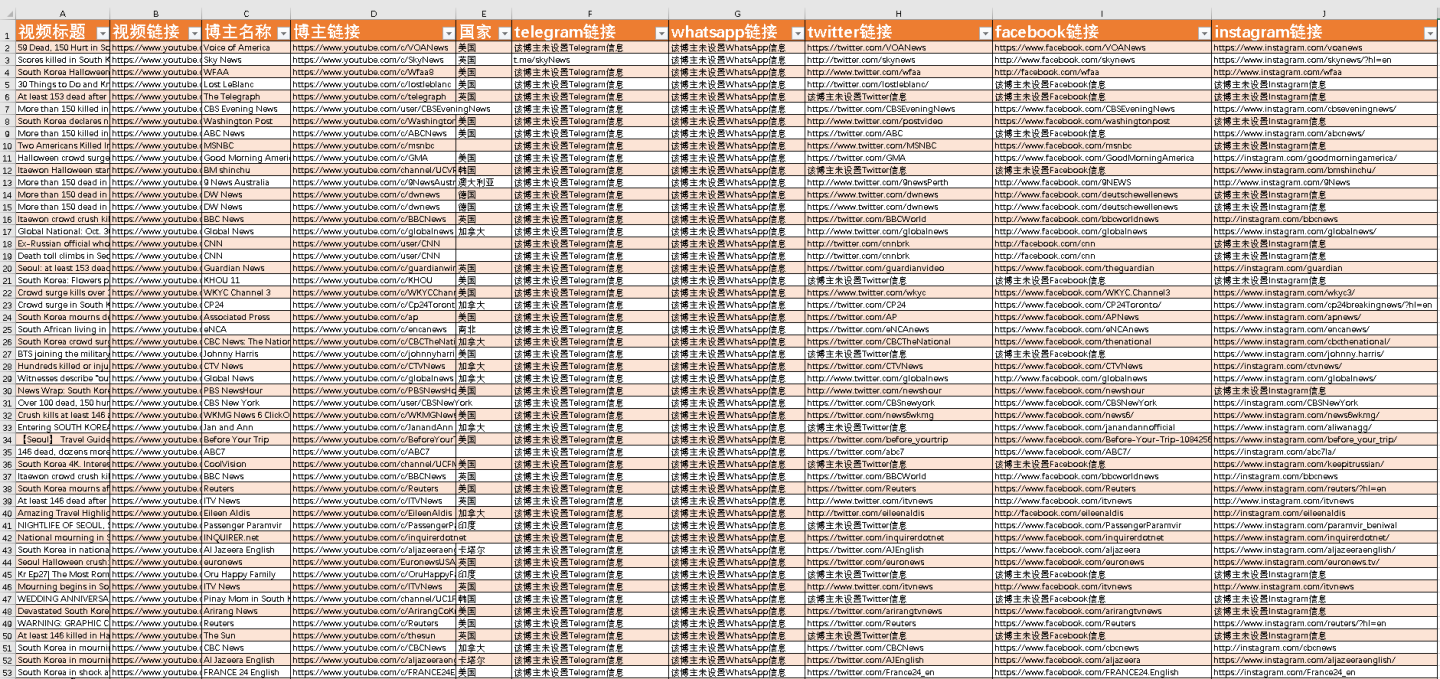
实现思路:
通过按指定关键词搜索视频,通过视频进入博主的主页简介,爬取博主的各种联系信息。
并把源码封装成exe文件,方便没有python环境,或者不懂技术的人使用它。
二、代码讲解
2.1 爬虫
本爬虫是通过selenium模拟手工搜索的过程,所以需要提前安装好chrome浏览器和chromedriver驱动。
安装chrome浏览器和chromedriver驱动的过程,请自行解决,不再赘述。
把chromedriver放到exe文件的旁边(同级目录下)即可。
展示部分核心代码:
初始化csv文件:
def init(self):
with open(f\'{self.query}.csv\', \'a\', newline=\'\', encoding=\'utf_8_sig\') as f:
writer = csv.writer(f)
writer.writerow([\'视频标题\', \'视频链接\', \'博主名称\', \'博主链接\', \'国家\', \'telegram链接\', \'whatsapp链接\', \'twitter链接\', \'facebook链接\', \'instagram链接\'])
爬博主信息:
# 先解析出所有链接
contact_url_els = self.browser.find_elements(By.XPATH, \'//*[@id=\"link-list-container\"]/a\')
for j in contact_url_els:
url = j.get_attribute(\'href\')
if \"t.me\" in url: # 电报链接
de_url = unquote(url)
de_url_dict = parse_qs(urlparse(de_url).query)
url = de_url_dict.get(\"q\")[0]
telegram_url = url
if \"wa.link\" in url or \"api.whatsapp.com\" in url: # whatsapp链接
de_url = unquote(url)
de_url_dict = parse_qs(urlparse(de_url).query)
url = de_url_dict.get(\"q\")[0]
whatsapp_url = url
if \"twitter.com\" in url: # twitter链接
de_url = unquote(url)
de_url_dict = parse_qs(urlparse(de_url).query)
url = de_url_dict.get(\"q\")[0]
twitter_url = url
if \"facebook.com\" in url: # facebook链接
de_url = unquote(url)
de_url_dict = parse_qs(urlparse(de_url).query)
url = de_url_dict.get(\"q\")[0]
facebook_url = url
if \"instagram.com\" in url: # instagram链接
de_url = unquote(url)
de_url_dict = parse_qs(urlparse(de_url).query)
url = de_url_dict.get(\"q\")[0]
instagram_url = url
2.2 tkinter界面
界面部分代码:
# 创建主窗口
root = tk.Tk()
root.title(\'YouTube爬虫-定制化开发 | 马哥python说\')
# 设置窗口大小
root.minsize(width=850, height=650)
show_list_Frame = tk.Frame(width=800, height=450) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=120, anchor=\'nw\') # 摆放位置
# 滚动条
scroll = tk.Scrollbar(show_list_Frame)
# 放到Y轴竖直方向
scroll.pack(side=tk.RIGHT, fill=tk.Y)
2.3 存日志
软件运行过程中,会在同级目录下生成logs文件夹,文件夹内会出现log文件,记录下软件在整个运行过程中的日志,方便长时间运行、无人值守,出现问题后的debug。
部分代码:
class Log_week():
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = \'[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s\'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt=\'%Y-%m-%d %H:%M:%S\')
# info日志文件名
info_file_name = time.strftime(\"%Y-%m-%d\") + \'.log\'
# 将其保存到特定目录,ap方法就是寻找项目根目录,该方法博主前期已经写好。
case_dir = r\'./logs/\'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when=\'MIDNIGHT\',
interval=1,
backupCount=7,
encoding=\'utf-8\')
self.logger.addHandler(sh)
sh.setFormatter(log_formatter)
self.logger.addHandler(info_handler)
info_handler.setFormatter(log_formatter)
return self.logger
三、说明
我是 @马哥python说,持续分享python源码干货!
推荐阅读: 【爬虫+情感判定+Top10高频词+词云图】\"乌克兰\"油管热评python舆情分析
来源:https://www.cnblogs.com/mashukui/p/16849782.html
本站部分图文来源于网络,如有侵权请联系删除。