 百木园
百木园目录
- 一、管理方式
- 二、结构维护
- 三、数据调度
- 1、同步方案
- 2、中断和恢复
- 四、刷新策略
- 五、深度分页
- 六、参考源码
Index用不好,麻烦事不会少;
一、管理方式
ElasticSearch作为最常用的搜索引擎组件,在系统架构中发挥极其重要的能力,可以极大的提升数据的加载和检索效率;但不可否认的是,在长期的应用实践中,也发现很多不好处理的流程和场景;
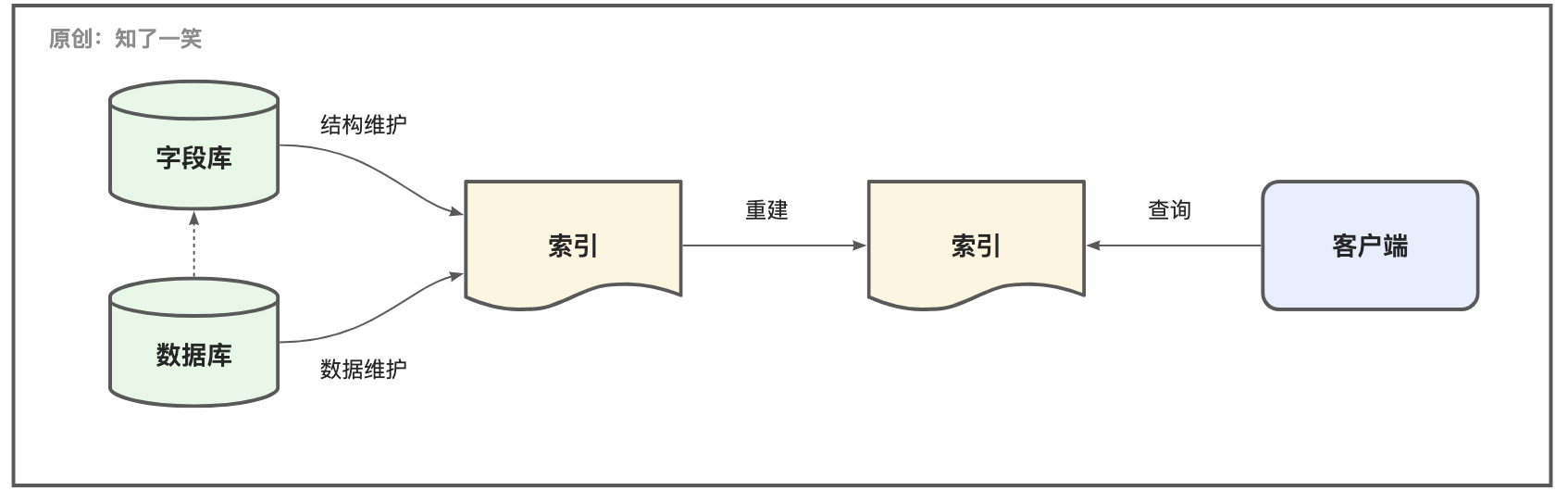
从直观感觉上说,业务中对索引的使用主要涉及如图的几个流程,其核心也就是索引的结构维护与数据的流动管理两个模块;
如果数据结构比较简单且体量小,那么使用起来可能很顺手;如果数据主体复杂且会动态扩展,并且体量偏大,那么就很容易踩中一些比较坑的点;
比如:索引中字段一旦有误,调整的流程十分复杂;数据流向索引中的方式,需要根据场景灵活选择;以及数据查询时的深度分页问题;下面将围绕这些问题来总结下应对策略;
顺带补充一句,其实很多组件在应用的时候都有不太符合预期的地方,所以在集成时可以考虑编写自定义的管理程序,来解决使用时可能存在的问题;
二、结构维护
对于ES索引的结构维护,数据主体如果相对简单的话,可以考虑手动管理,但实际上使用索引时,通常主体结构都比较复杂,字段个数超过三五十都很常见,所以基于流程化的管理很有必要;
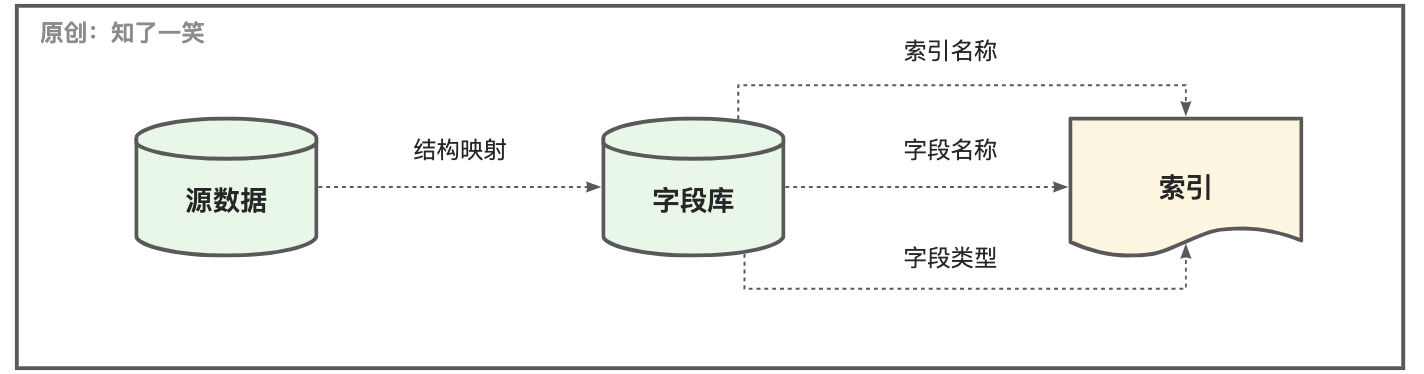
结构映射:将需要构建索引的主体结构,在字段库中统一维护,值得注意的是字段名称和类型,字段可以与关系型数据库的查询一致,但是不同组件类型的描述不一样,尤其对ES来说,如果字段类型不合理,会影响搜索的使用;
索引结构:在实际的业务场景中,字段的信息是会动态变化的,这就会给索引结构的维护带来很多麻烦,字段的增减都好管理,但是如果涉及类型的变动,则存在索引重建的过程,会导致数据多次重新调度,这也是风险较高的操作;
程序维护:这种结构维护的机制,其核心目的是把整个流程进行程序化管理,避免人工进行干预,以此来确保索引结构的稳定扩展;
不得不提的一个经验教训,曾经在管理业务日志的索引结构时,出现过一次误删动作,好在可以重新构建和数据备份恢复,但是依旧给心里留下了几厘米的阴影,此后也将维护流程彻底程序化,避免失误动作发生;
三、数据调度
1、同步方案
数据的调度管理,其本质就是将数据从一个容器向另一个容器搬运或者拷贝,其核心操作就是读和写两个动作,但是为了让流程具备容错和稳定性,通常需要做策略和方案的设计;
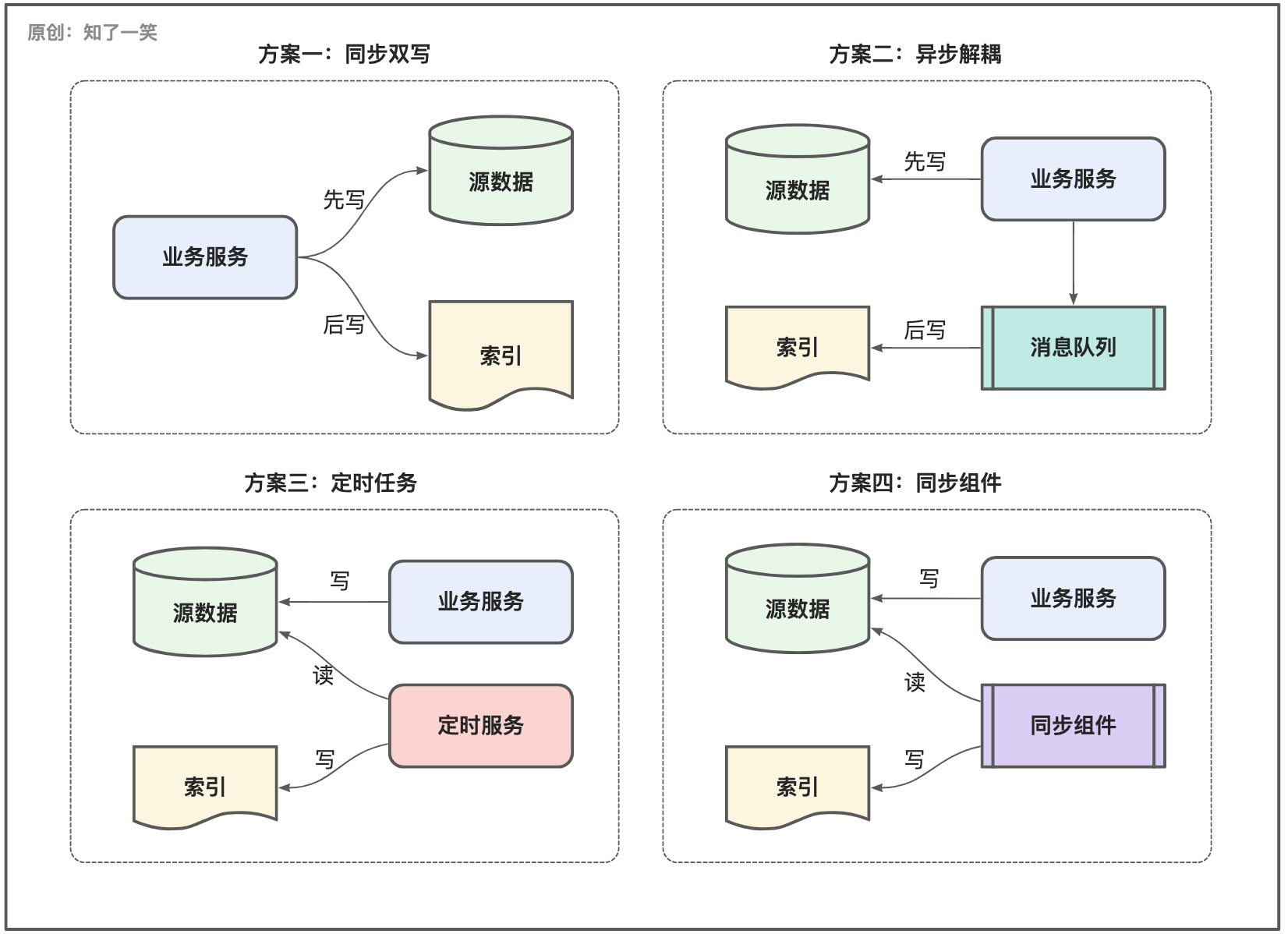
同步双写:对数据的实时性要求极高,通常在一个事务中完成数据的双写动作,保证数据层面的强一致性;
异步解耦:在完成数据库的写动作之后,基于MQ消息解耦索引的写入,流程存在轻微的延迟,如果消费失败会导致数据缺失;
定时任务:通过任务调度的方式,以指定的时间周期执行新增数据的同步机制,存在明显的时效问题;
组件同步:采用合适的同步组件,比如官方提供的组件或者一些第三方开源的组件,在原理上与任务同步类似;
数据同步的选型方案有多种,如何选择完全看具体的场景,在过往的使用过程中,对于核心业务会采用同步双写,对于内部的活动类业务会采用异步的方式,对于业务日志会采用任务调度,对于系统的监控或执行日志则多是依赖同步组件;
2、中断和恢复
无论采用何种方式将数据同步到索引中,都不得不面对一个灵魂问题,如果流程突然异常中断,恢复后如何保证索引数据不丢失?这个问题适应于很多复杂的流程;
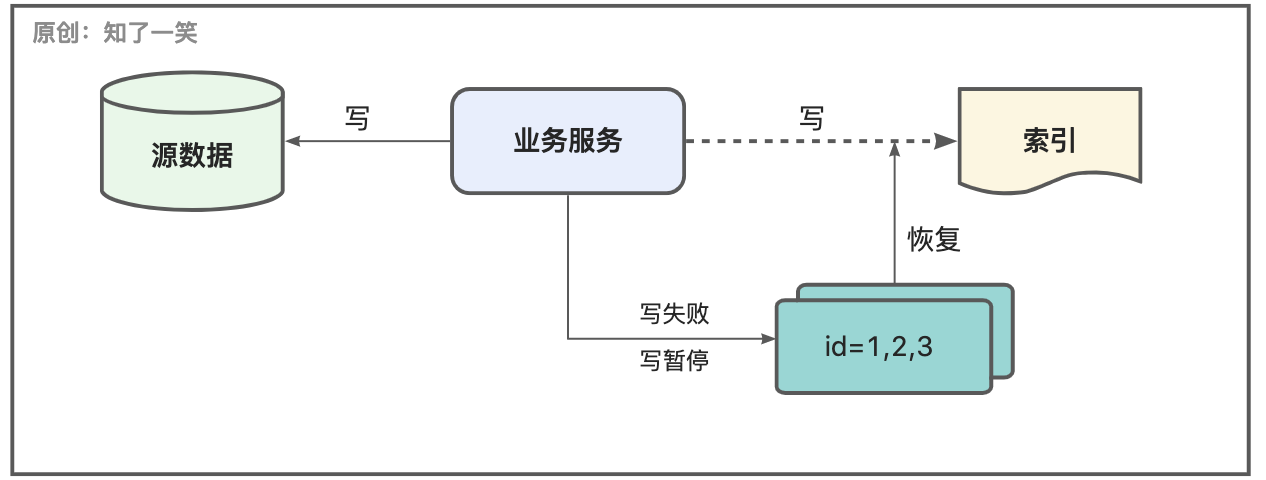
容错性是衡量一个复杂流程的核心指标,比如在索引数据同步的过程,需要短暂性的暂停,或者流程被迫中断时,都应该具备恢复后自动修复索引中数据缺失的能力;
ES实践中一个非常经典的问题,修改索引的结构时需要进行索引重建,此时要将当前索引迁入临时索引中,在完成索引结构调整之后,需要从临时索引中迁回数据,在此过程中,可以对服务交互的索引名称动态调整;
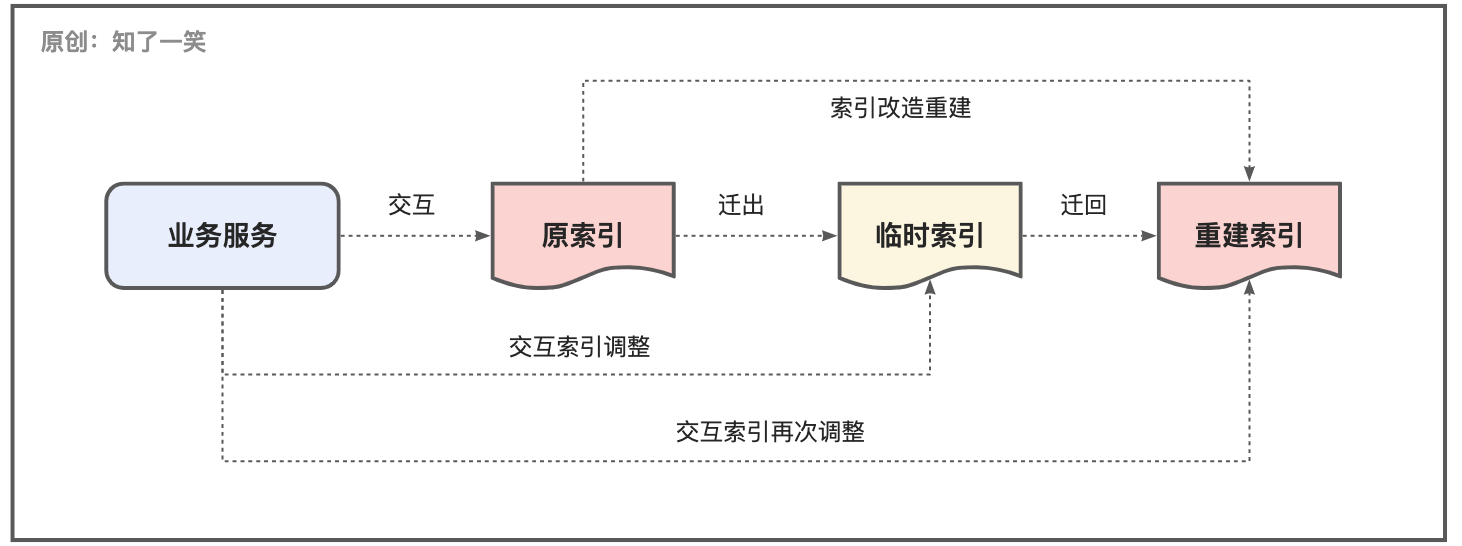
当然也可以直接使用临时索引作为交互索引,避免一次迁移动作,这种动态的识别需要在服务中嵌入,在整个reindex过程中要避免手动干预,个人还是更相信程序的安全性和准确性;
四、刷新策略
在向ES索引中写数据时,存在三种不同的数据刷新机制,查看6.8版本的设置中,参数refresh_interval设置的是1s时间,即执行写入动作1秒后数据才可以被搜索到,避免频繁写入消耗过多的资源;
NONE:默认的刷新策略,请求提交之后不会等待数据刷新,降低资源消耗但数据实时性低;
IMMEDIATE:请求提交后立即刷新索引,数据的实时性很高但是资源消耗过大,API文档中建议测试使用;
WAIT_UNTIL:请求提交之后会等待索引刷新完成才会结束,相对来说是一种比较平衡的策略;
刷新机制对于索引的数据维护来说,主要在增删改的动作中,对即时查询有直接的影响,至于如何选择还是要结合具体的场景,尤其与同步方案关联密切,也可以在索引交互中动态维护策略,来应对不时之需;
五、深度分页
对于数据查询来说,几乎都存在分页的需求,在常见的应用中,不断下拉的功能都是存在最大的极限值;
ES中常用From/Size进行分页查询,但是存在一个限制,在索引的设置中存在max_result_window分页深度的限制,6.8版本默认值是10000条,即10000之后的数据无法使用From/Size翻页;
先从实际应用场景来分析,大多数的翻页需求最多也就前10页左右,所以从这个角度考虑,ES的翻页限制在合理区间,在实践中也存在对部分索引调高的情况,暂未出现明显问题;
再从技术角度来思考一下,如果翻页的参数过大意味着更多的数据过滤,那计算资源的占用也会升高,ES引擎的强大在于搜索能力,检索出符合要求的数据即可;
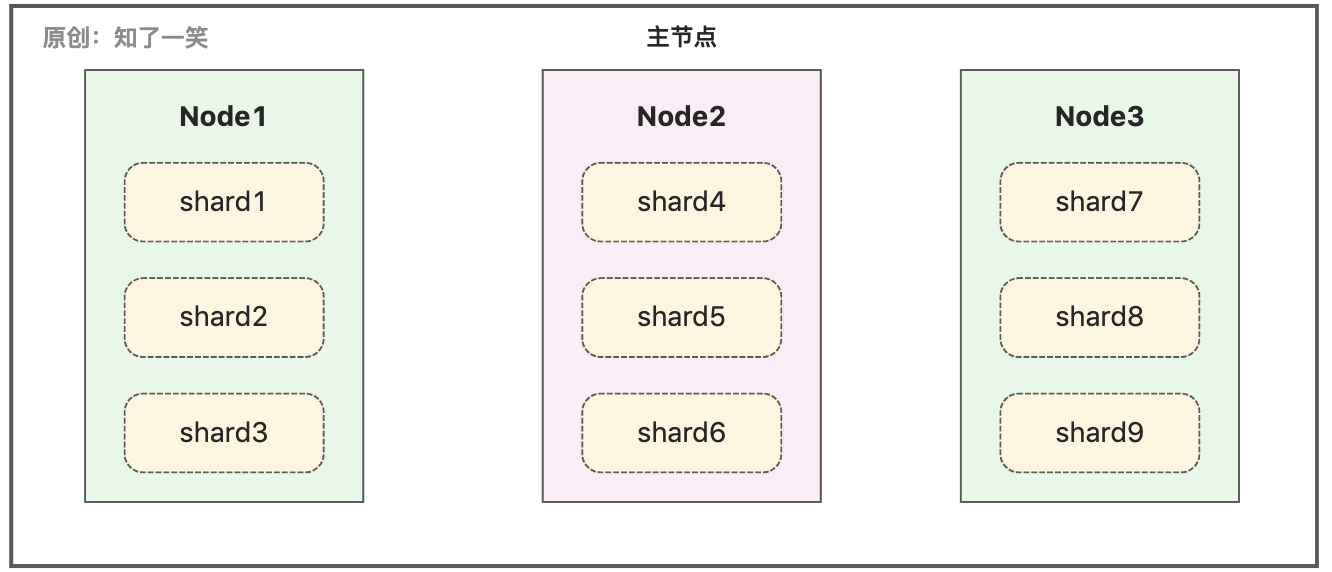
不管是ES还是其它类似的分布式存储组件,甚至是MySQL分库分表模式,其本质都是数据分布在不同服务节点的不同数据片上;常规的执行原理都是给请求分配一个主节点,协调各个节点执行相同的查询,并完成结果汇总和响应,深度分页时计算资源的占用自然非常高;
如果一定需要深度分页,在6.8的版本中提供了Scroll或Search-After两种其他的方式,用法参考相关文档即可。
六、参考源码
编程文档:
https://gitee.com/cicadasmile/butte-java-note
应用仓库:
https://gitee.com/cicadasmile/butte-flyer-parent
Gitee主页: https://gitee.com/cicadasmile/butte-java-note
来源:https://www.cnblogs.com/cicada-smile/p/16856506.html
本站部分图文来源于网络,如有侵权请联系删除。