 百木园
百木园您好,我是湘王,这是我的博客园,欢迎您来,欢迎您再来~
Lambda表达式虽然将接口作为代码块赋值给了变量,但如果仅仅只是Lambda表达式,还无法让Java由量变引起质变。真正让Lambda能够发挥出巨大威力的,就是流式计算。
所谓流式计算,就是让数据像在流水线上一样,从一道工序流转到下一道工序。就像这样:
如果把数据处理的方式比作流水线,那么Spark、Storm和Flink就是目前市面上头部的三家工厂。它们有各种各样的数据装配间(也就是各种处理数据的算子),将数据按照所需加工成型。所以,不懂流式计算根本就做不了大数据开发。上面那张图,如果换成流式计算的,就是这样:
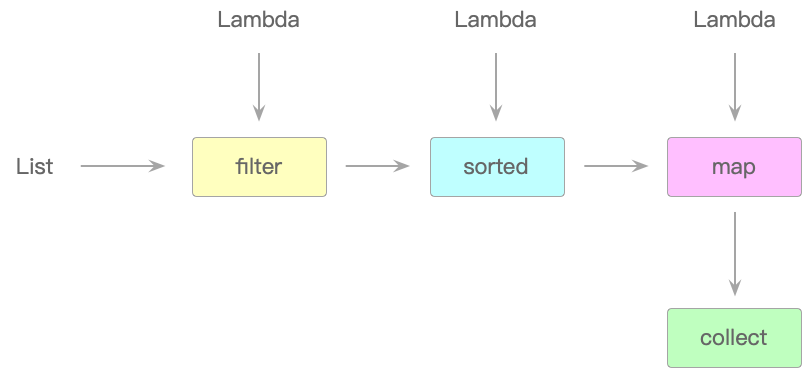
Lambda表达式就变成了一个个的数据装配间。
还是以实际的代码例子来说明。假如有这样的代码:
/**
* 雇员数据
*
* @author 湘王
*/
public class Employee {
public enum Type { MANAGER, SELLER, OFFICER };
private String name;
private String genger;
private Integer age;
private boolean married;
private Type type;
public Employee(final String name, final String genger, final Integer age, final boolean married, final Type type) {
super();
this.name = name;
this.genger = genger;
this.age = age;
this.married = married;
this.type = type;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGenger() {
return genger;
}
public void setGenger(String genger) {
this.genger = genger;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public boolean isMarried() {
return married;
}
public void setMarried(boolean married) {
this.married = married;
}
public Type getType() {
return type;
}
public void setType(Type type) {
this.type = type;
}
@Override
public String toString() {
return this.name + \"(\" + this.genger + \")-\" + this.age;
}
}
如果想筛选28岁以下的员工,并按年龄排序,用老办法只能这么做:
List<Employee> employees = Arrays.asList(
new Employee(\"张勇\", \"男\", 28, true, Employee.Type.MANAGER),
new Employee(\"李强\", \"男\", 22, false, Employee.Type.SELLER),
new Employee(\"王武\", \"男\", 32, false, Employee.Type.SELLER),
new Employee(\"梅丽\", \"女\", 26, true, Employee.Type.OFFICER),
new Employee(\"郑帅\", \"男\", 29, false, Employee.Type.OFFICER),
new Employee(\"曾美\", \"女\", 27, true, Employee.Type.SELLER),
new Employee(\"郝俊\", \"男\", 22, true, Employee.Type.SELLER),
new Employee(\"方圆\", \"女\", 24, false, Employee.Type.SELLER)
);
// 传统筛选数据的方法
// 筛选28岁以下的员工
List<Employee> list1 = new ArrayList<>();
for(Employee employee : employees) {
if (employee.getAge() < 28) {
list1.add(employee);
}
}
// 按年龄排序
list1.sort(new Comparator<Employee>() {
@Override
public int compare(Employee o1, Employee o2) {
return o1.getAge().compareTo(o2.getAge());
}
});
如果要转换成Lmabda表达式的话,就是这样:
/**
* 雇员函数式接口
*
* @author 湘王
*/
@FunctionalInterface
public interface EmployeeInterface<T> {
boolean select(T t);
}
public static List<Employee> filter(List<Employee> employees, EmployeeInterface<Employee> ei) {
List<Employee> list = new ArrayList<>();
for(Employee employee : employees) {
if (ei.select(employee)) {
list.add(employee);
}
}
return list;
}
// 使用Lambda表达式得到28岁以下的员工
List<Employee> list2 = filter(employees, employee -> employee.getAge() < 28);
// 按年龄排序
list2.sort((e1, e2) -> e1.getAge().compareTo(e2.getAge()));
可以看到,这虽然用了Lambda表达式替代了旧的方法,但可能要写大量的函数式接口,Lambda沦为鸡肋,完全谈不上简便快速,更别说优雅!
所以,这时候如果用流式计算,那简直不要太优雅:
// Lambda表达式 + 流式计算
List<Employee> list3 = employees
// 生成「流」
.stream()
// 过滤
.filter(emp -> emp.getAge() < 28)
// 排序
.sorted((o1, o2) -> o1.getAge().compareTo(o2.getAge()))
// 生成新的结果集合
.collect(Collectors.toList());
仅仅几行代码就搞定了,完全没有之前那种「傻大黑粗」的感觉了。
上面的代码,可以用这幅图来还原:
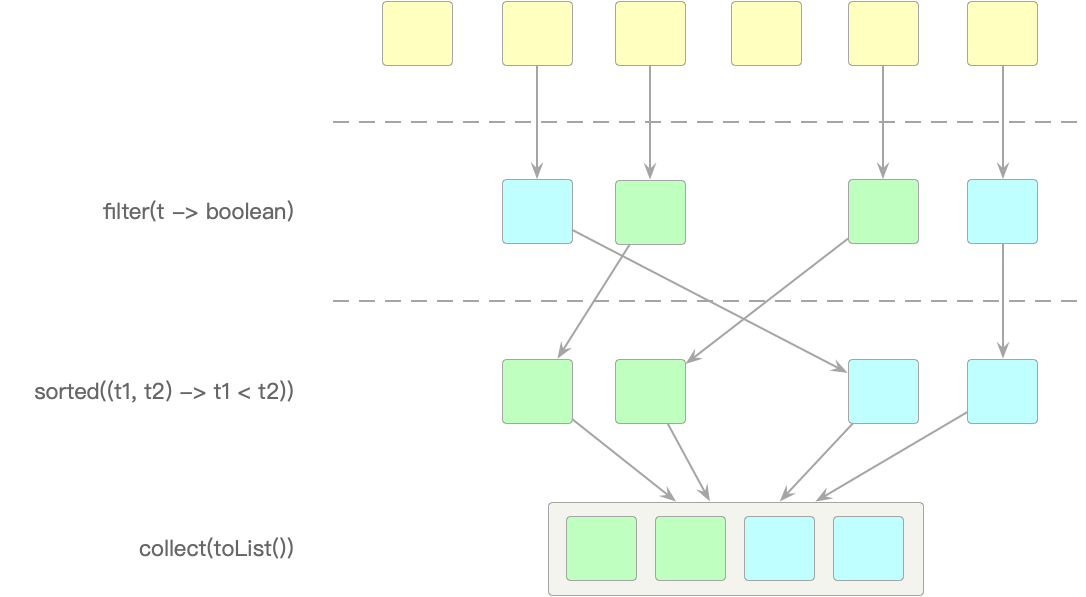
1、先用filter算子(流式计算中的函数,或者方法,在大数据中统称为算子,我也习惯这么称呼)将符合年龄条件的雇员筛选出来;
2、再按照年龄从低到高排序;
3、将排好序的员工列表输出出来。
就是这么简单粗暴!
就像藏宝图一样,只有将Lambda表达式和流式计算这两张碎片拼起来,才是完整的Java函数式编程。
所有的流式计算算子可以分为两大类:中间操作和终端操作。
1、中间操作:返回另一个流,如filter、map、flatMap等;
2、终端操作:从流水线中生成结果,如collect、count、reduce、forEach等。
现在,咱们已经找到了函数式编程这个宝藏。那么再回到最初的问题:当要实现某宝、某东和某哈哈的员工联谊并解决单身问题时,有更好的办法吗?
当然有,而且只用一行代码就可以搞定:
List<Employee> unMarriedList4 = list.stream().filter(company -> Company.Type.BIG == company.getType()).flatMap(companys -> companys.getEmployees().stream()).filter(Employee::isMarried).sorted(Comparator.comparing(Employee::getAge)).collect(Collectors.toList());
感谢您的大驾光临!咨询技术、产品、运营和管理相关问题,请关注后留言。欢迎骚扰,不胜荣幸~
来源:https://www.cnblogs.com/xiangwang1111/p/16864384.html
本站部分图文来源于网络,如有侵权请联系删除。