 百木园
百木园接口优化过程记录
问题背景
某个接口耗时长(247ms),但里面逻辑不算复杂,只进行了简单的对象引用以及操作了多次Redis
步骤1:链路追踪,确定业务耗时点
接口里通过链路追踪以及日志查询发现主要是操作Redis的这条链路耗时变长
步骤2:从Redis找问题,列出可能点
原因可能是:
- Redis本身存在问题,可能是命令复杂度、IO、连接数不够、过载等
- 网络原因,获取连接或者是数据传输耗时
经测试发现以下这些问题
-
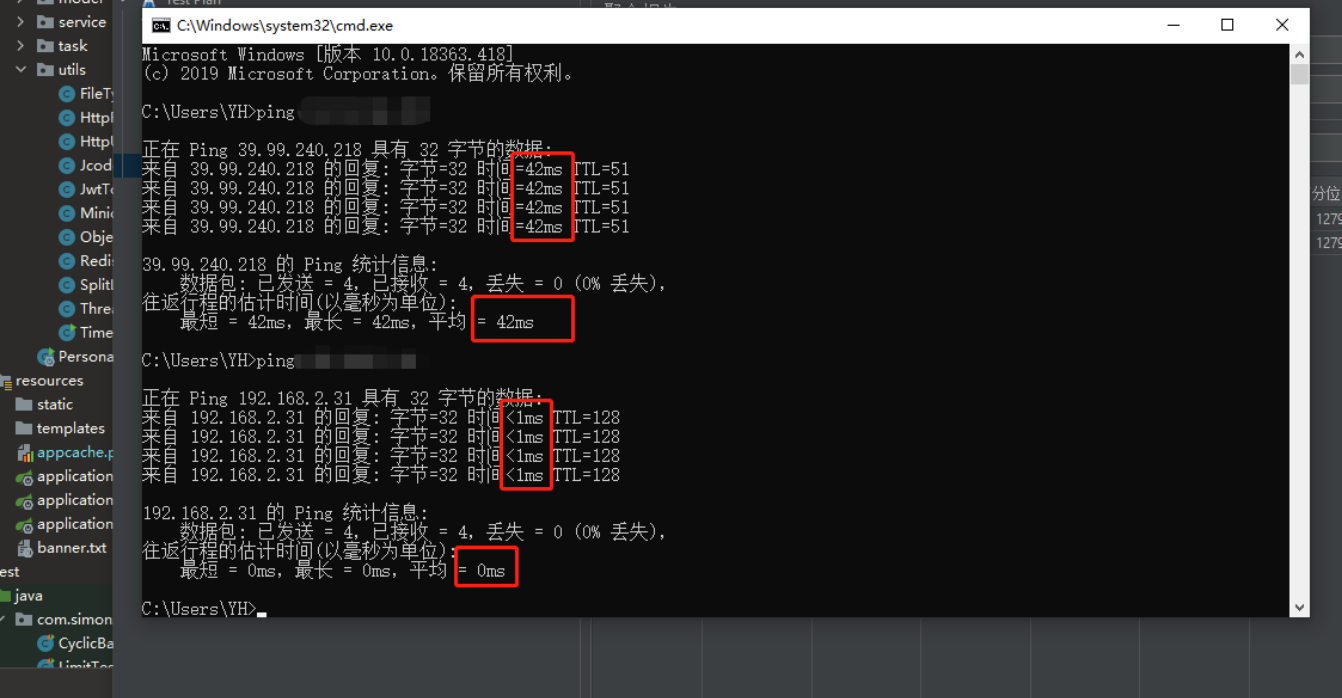
使用本机ping服务器,网络延迟大概在42ms(ping内网<1ms,ping公司线上环境7ms),属于 高延迟
-
内部逻辑对获取Redis连接进行耗时记录,发现除首次获取连接需30ms,后续获取连接耗时 <1ms,
-
内部对Redis的一个get操作需要47ms(高耗时)

步骤二总结:
- 调用方与客户端的网络高延迟
- 普通的get操作需要47ms不排除Redis本身存在问题,需要继续排查
步骤3:从Redis内部排查
3.1从服务器内部查看延迟峰值
由于Redis是使用Docker搭建,在虚拟化环境可能会差一些,不过还是先查看延迟峰值以及平均响应时 间
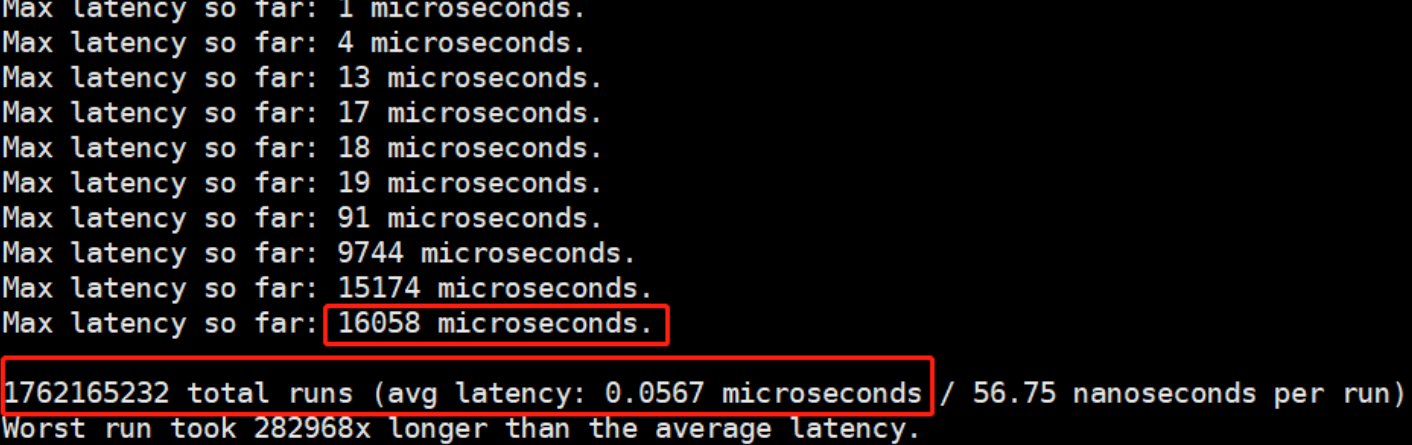
100秒内测试结果
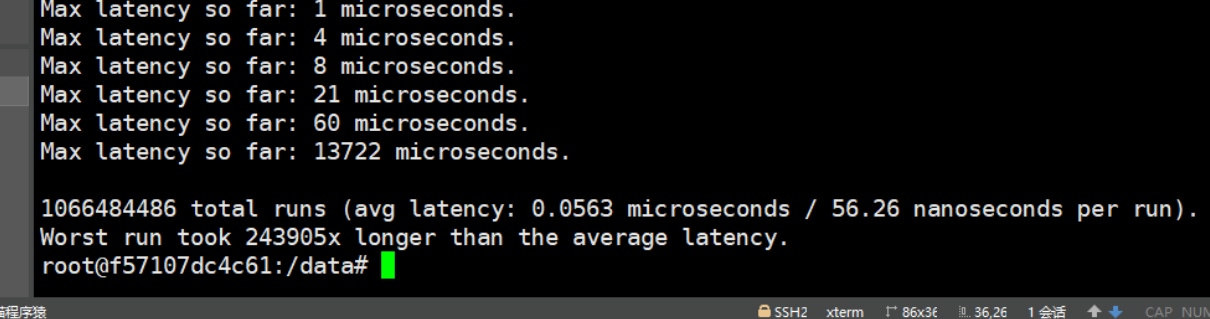
60秒内测试结果
从测试数据可以看出
- 在100秒时,最大延迟为16ms,处理了1,762,165,232次命令平均响应时间为0.053ms
- 在60秒时,最大延迟为14ms,处理了1,066,484,486次命令平均响应时间为0.056ms
总结:从这一测试数据看单一get命令是不会到40+ms
3.2设置慢命令时间
通过给Redis设置slowlog时间为5ms,从业务代码里操作set和get命令各200条,均无发现slowlog。
3.3命令复杂度过高(略)
接口里使用的命令只是简单的get,set操作,并不是SORT、SUNION等聚合类容易导致操作延迟变大的 命令。
且O(N)里的N值并不大,也不需要花费很多时间在数据协议的组装和网络传输过程中。
所以该指标不做测试。⚠ Ps:若是想测试该指标也可用slowlog进行排查。
3.4bigkey(略)
接口里操作的都不是bigkey,该指标不做测试。有需要可先使用redis命令扫描bigkey。注意:扫描时与 上述提到的延迟峰值都会使Redis的OPS突增。
3.5集中过期(略)
该Redis里并没有过多数据,该指标不做测试。
3.6实例内存达到上限
从数据上来看,内存并没有使用很多。
3.7fork耗时严重(略)
如3.5中所说,该指标不做测试
3.8连接数问题
从springboot里使用了nio开发的lettuce Redis线程池,当设置连接数为500时,在代码层面开启多个线 程一直跑,Redis客户端连接数可以达到峰值,所以这块暂时没有问题。
暂时总结
根据上述数据总结出99%是网络问题造成的获取数据延迟。当然还有很多指标都没有列举,例如:是否 开启内存大页、是否开启AOF造成Redis、或者是是否使用Swap等。由于服务器的Redis也算比较简 单,这些也就默认是正常了
后续执行
后续可以再继续监控
- 观察连接数,是否有频繁的短连接消耗
- 以及对Redis的各个指标进行监控
来源:https://www.cnblogs.com/checkcode/p/speedUpdate_1.html
本站部分图文来源于网络,如有侵权请联系删除。