 百木园
百木园前言
今天给大家介绍的是Python爬取螺蛳粉商品数据,在这里给需要的小伙伴们代码,并且给出一点小心得。
首先是爬取之前应该尽可能伪装成浏览器而不被识别出来是爬虫,基本的是加请求头,但是这样的纯文本数据爬取的人会很多,所以我们需要考虑更换代理IP和随机更换请求头的方式来对螺蛳粉数据进行爬取。
在每次进行爬虫代码的编写之前,我们的第一步也是最重要的一步就是分析我们的网页。
通过分析我们发现在爬取过程中速度比较慢,所以我们还可以通过禁用谷歌浏览器图片、JavaScript等方式提升爬虫爬取速度。

开发工具
Python版本: 3.6
相关模块:
requests模块
json模块
re模块
time模块
xlwt模块
xlrd模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
思路分析
浏览器中打开我们要爬取的页面
按F12进入开发者工具,查看我们想要的螺蛳粉商品数据在哪里
这里我们需要页面数据就可以了
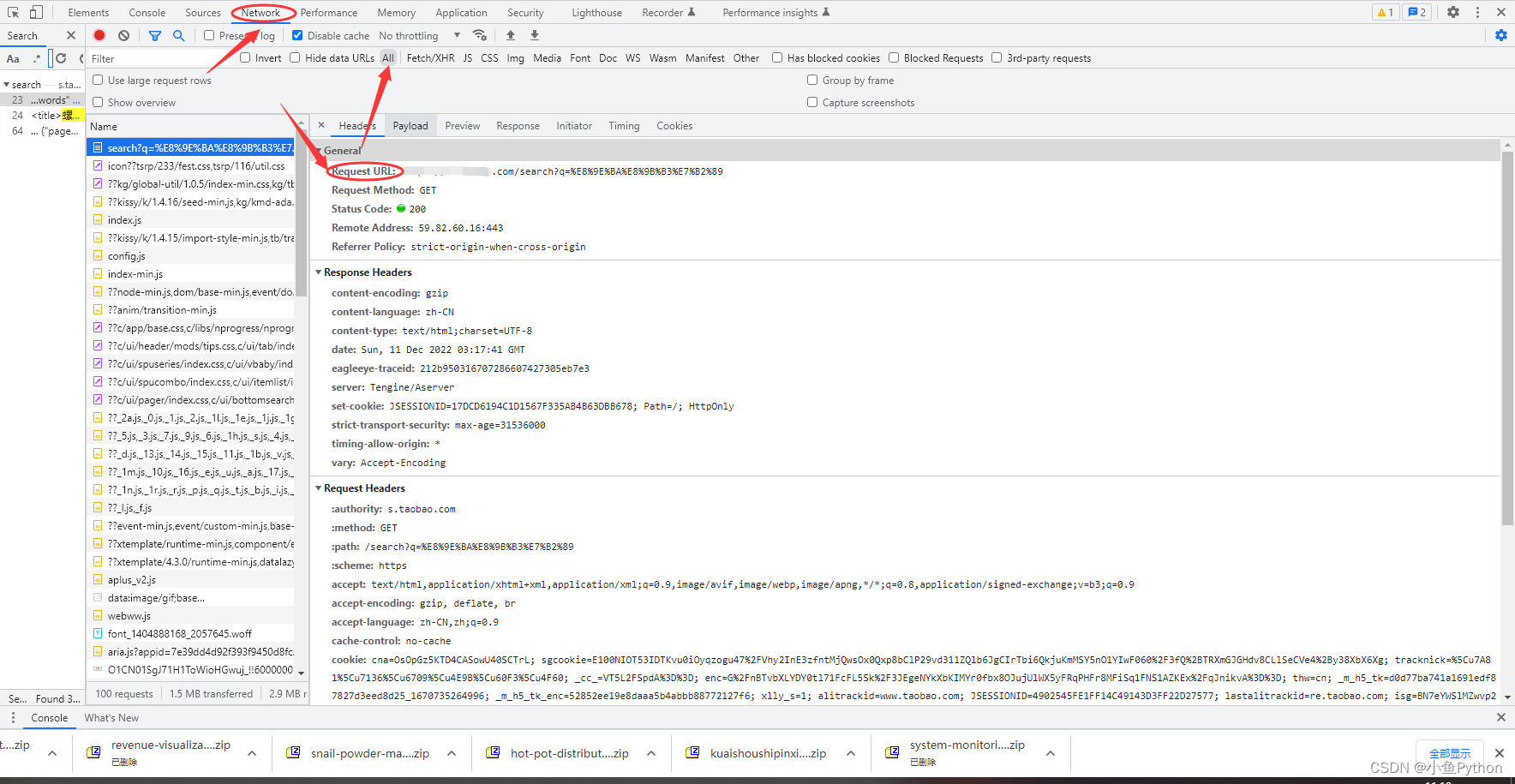
代码实现
headers = {
#\'Host\':\'s.taobao.com\',
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36\',
\'cookie\':\'你的Cookie\',
\'accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\',
\'accept-encoding\': \'gzip, deflate, br\',
\'accept-language\': \'zh-CN,zh;q=0.9\',
\'upgrade-insecure-requests\': \'1\',
\'referer\':\'https://www.taobao.com/\',
}
#请求网页内容
url=\"https://s.taobao.com/search?q=螺蛳粉&ie=utf8&bcoffset=0&ntoffset=0&s=0\"
#requests+请求头headers
r = requests.get(url, headers=headers)
r.encoding = \'utf8\'
s = (r.content)
#乱码问题
html = s.decode(\'utf8\')
# 初始化execl表
def initexcel():
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding=\'utf-8\')
# 创建一个worksheet
worksheet = workbook.add_sheet(\'sheet1\')
workbook.save(\'螺蛳粉.xls\')
##写入表头
value1 = [[\"标题\", \"销售地\", \"销售量\", \"评论数\", \"销售价格\", \'商品惟一ID\', \'图片URL\']]
book_name_xls = \'螺蛳粉.xls\'
write_excel_xls_append(book_name_xls, value1)
# 正则模式
p_title = \'\"raw_title\":\"(.*?)\"\' #标题
p_location = \'\"item_loc\":\"(.*?)\"\' #销售地
p_sale = \'\"view_sales\":\"(.*?)人付款\"\' #销售量
p_comment = \'\"comment_count\":\"(.*?)\"\'#评论数
p_price = \'\"view_price\":\"(.*?)\"\' #销售价格
p_nid = \'\"nid\":\"(.*?)\"\' #商品惟一ID
p_img = \'\"pic_url\":\"(.*?)\"\' #图片URL
# 数据集合
data = []
# 正则解析
title = re.findall(p_title,html)
location = re.findall(p_location,html)
sale = re.findall(p_sale,html)
comment = re.findall(p_comment,html)
price = re.findall(p_price,html)
nid = re.findall(p_nid,html)
img = re.findall(p_img,html)
for j in range(len(title)):
data.append([title[j],location[j],sale[j],comment[j],price[j],nid[j],img[j]])
# 写入execl
def write_excel_xls_append(path, value):
index = len(value) # 获取需要写入数据的行数
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
new_worksheet.write(i+rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入
new_workbook.save(path) # 保存工作簿
#保存数据
book_name_xls = \'螺蛳粉.xls\'
write_excel_xls_append(book_name_xls, data)
time.sleep(6)
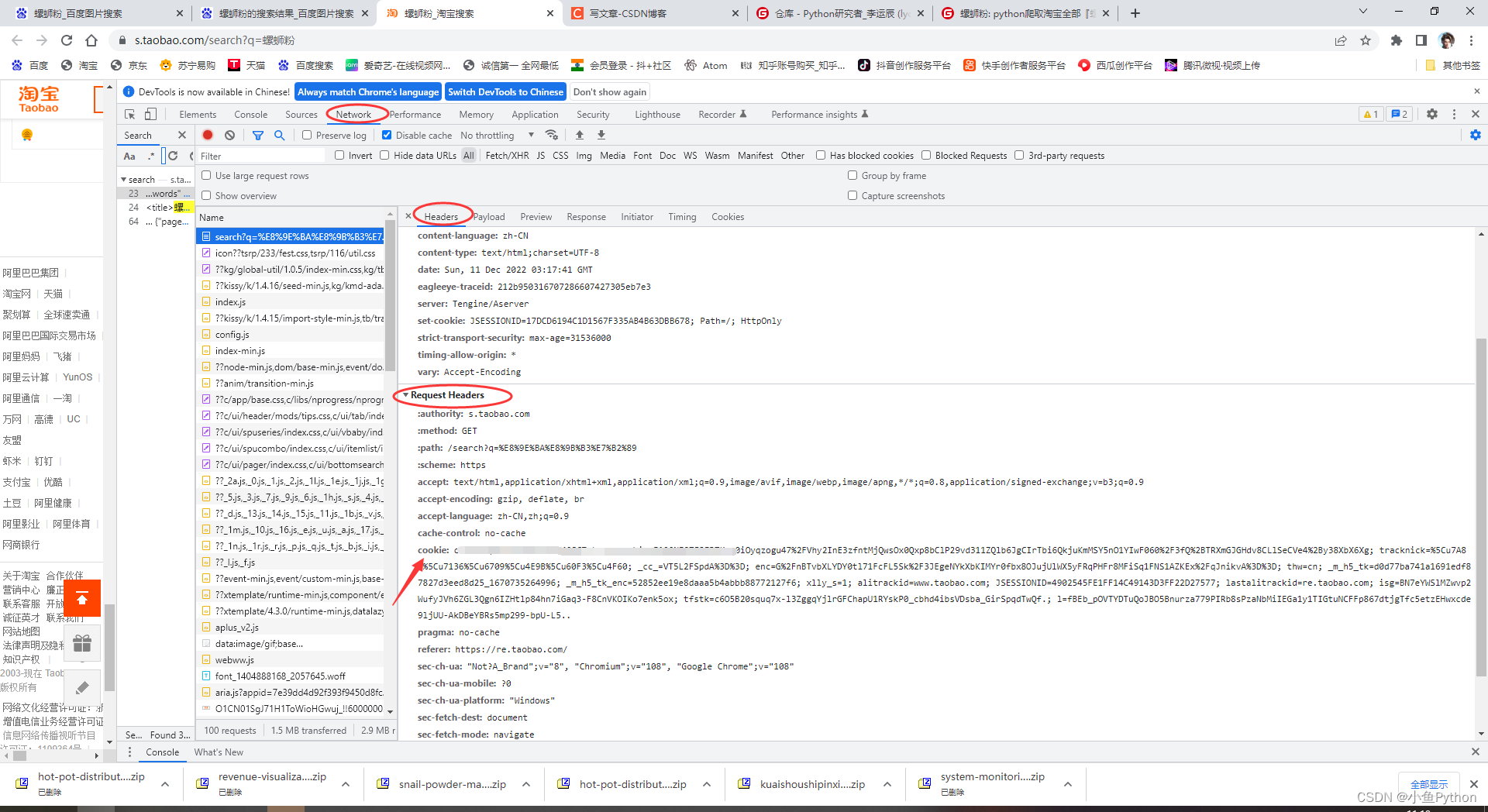
如何获取Cookie
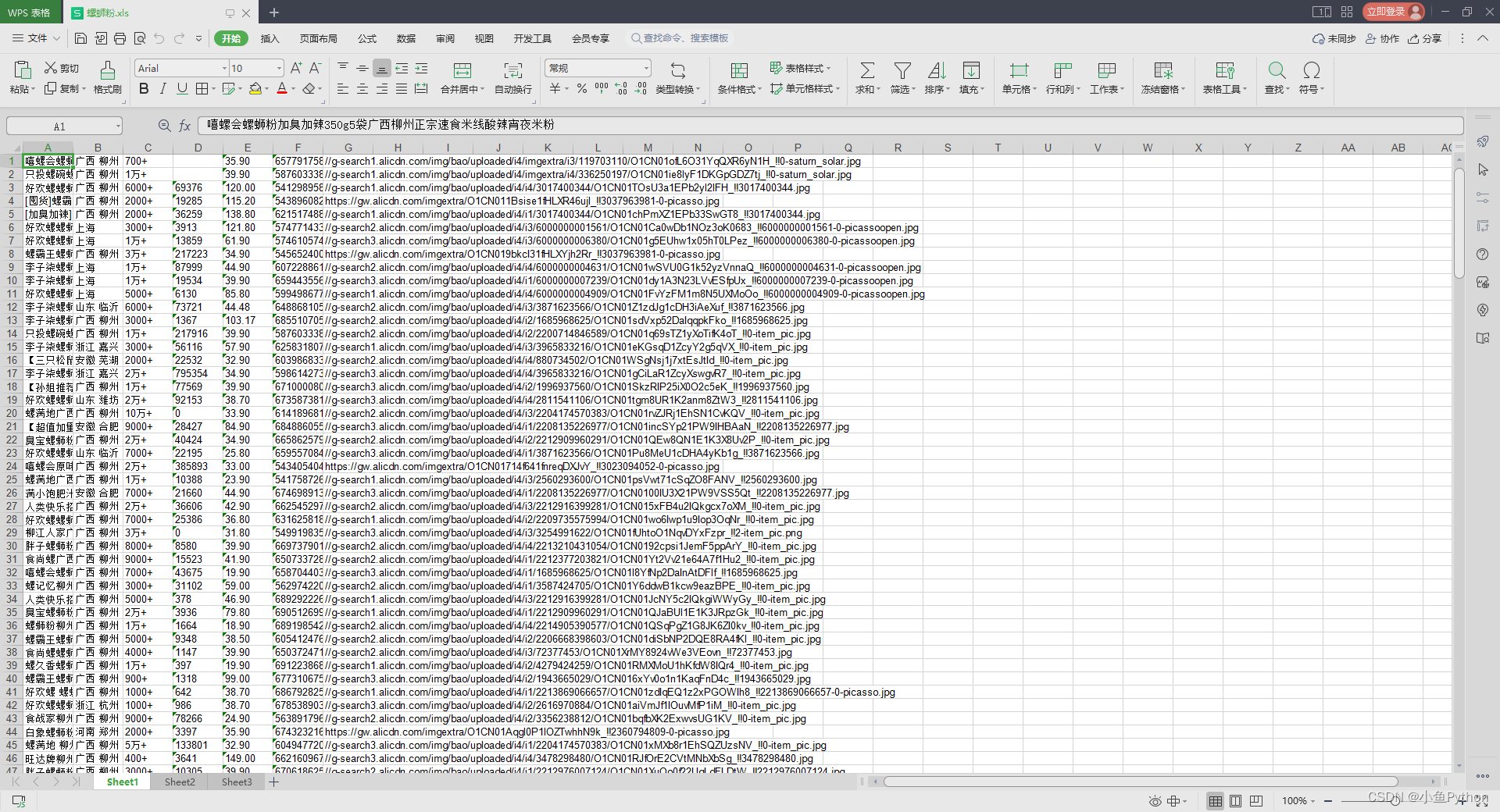
结果展示
最后
今天的分享到这里就结束了 ,感兴趣的朋友也可以去试试哈
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/
来源:https://www.cnblogs.com/guzichuan/p/16973644.html
本站部分图文来源于网络,如有侵权请联系删除。