 百木园
百木园MySQL数据模型
关系型数据库是建立在关系模型基础上的数据库,简单说,关系型数据库是由多张能互相连接的 二维表 组成的数据库
关系型数据库的优点:
- 都是使用表结构,格式一致,易于维护。
- 使用通用的 SQL 语言操作,使用方便,可用于复杂查询。
- 关系型数据库都可以通过SQL进行操作,所以使用方便。
- 复杂查询。现在需要查询001号订单数据,我们可以看到该订单是1号客户的订单,而1号订单是李聪这个客户。以
- 后也可以在一张表中进行统计分析等操作。
- 数据存储在磁盘中,安全。
SQL分类
- DDL(Data Definition Language) : 数据定义语言,用来定义数据库对象:数据库,表,列等
DDL简单理解就是用来操作数据库,表等
- DML(Data Manipulation Language) 数据操作语言,用来对数据库中表的数据进行增删改
DML简单理解就对表中数据进行增删改
- DQL(Data Query Language) 数据查询语言,用来查询数据库中表的记录(数据)
DQL简单理解就是对数据进行查询操作。从数据库表中查询到我们想要的数据。
- DCL(Data Control Language) 数据控制语言,用来定义数据库的访问权限和安全级别,及创建用户
DML简单理解就是对数据库进行权限控制。比如我让某一个数据库表只能让某一个用户进行操作等。
| 注意: 以后我们最常操作的是 DML 和 DQL ,因为我们开发中最常操作的就是数据。 |
DDL:操作数据库
查询所有的数据库
- 运行上面语句效果如下:
SHOW DATABASES;
创建数据库
-
创建数据库:
CREATE DATABASE 数据库名称;
而在创建数据库的时候,我并不知道datastu数据库有没有创建,直接再次创建名为db1的数据库就会出现错误。
-
创建数据库(判断,如果不存在则创建)
CREATE DATABASE IF NOT EXISTS 数据库名称;-
删除数据库
DROP DATABASE 数据库名称;-
删除数据库(判断,如果存在则删除)
DROP DATABASE IF EXISTS 数据库名称;使用数据库
数据库创建好了,要在数据库中创建表,得先明确在哪儿个数据库中操作,此时就需要使用数据库。
-
使用数据库
USE 数据库名称;-
查看当前使用的数据库
SELECT DATABASE();查询表
-
查询当前数据库下所有表名称
SHOW TABLES;-
查询表结构
DESC 表名称;-
创建表
CREATE TABLE 表名 (
字段名1 数据类型1,
字段名2 数据类型2,
…
字段名n 数据类型n
);
注意:最后一行末尾,不能加逗号
create table tb_user (
id int,
username varchar(20),
password varchar(32)
);数据类型
MySQL 支持多种类型,可以分为三类:
-
数值
tinyint : 小整数型,占一个字节 int : 大整数类型,占四个字节 eg : age int double : 浮点类型 使用格式: 字段名 double(总长度,小数点后保留的位数) eg : score double(5,2) -
日期
date : 日期值。只包含年月日 eg : birthday date : datetime : 混合日期和时间值。包含年月日时分秒 -
字符串
案例:
需求:设计一张学生表,请注重数据类型、长度的合理性
1. 编号
2. 姓名,姓名最长不超过10个汉字
3. 性别,因为取值只有两种可能,因此最多一个汉字
4. 生日,取值为年月日
5. 入学成绩,小数点后保留两位
6. 邮件地址,最大长度不超过 64
7. 家庭联系电话,不一定是手机号码,可能会出现 - 等字符
8. 学生状态(用数字表示,正常、休学、毕业...)语句设计如下:
create table student (
id int,
name varchar(10),
gender char(1),
birthday date,
score double(5,2),
email varchar(15),
tel varchar(15),
status tinyint
);删除表
-
删除表
DROP TABLE 表名;-
删除表时判断表是否存在
DROP TABLE IF EXISTS 表名;修改表
-
修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
-- 将表名student修改为stu
alter table student rename to stu;-
添加一列
ALTER TABLE 表名 ADD 列名 数据类型;
-- 给stu表添加一列address,该字段类型是varchar(50)
alter table stu add address varchar(50);-
修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
-- 将stu表中的address字段的类型改为 char(50)
alter table stu modify address char(50);-
修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
-- 将stu表中的address字段名改为 addr,类型改为varchar(50)
alter table stu change address addr varchar(50);-
删除列
ALTER TABLE 表名 DROP 列名;
-- 将stu表中的addr字段 删除
alter table stu drop addr;DML
DML主要是对数据进行增(insert)删(delete)改(update)操作。
添加数据
-
给指定列添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…);-
给全部列添加数据
INSERT INTO 表名 VALUES(值1,值2,…);-
批量添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
INSERT INTO 表名 VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
-
练习
为了演示以下的增删改操作是否操作成功,故先将查询所有数据的语句介绍给大家:
select * from stu;
-- 给指定列添加数据
INSERT INTO stu (id, NAME) VALUES (1, \'张三\');
-- 给所有列添加数据,列名的列表可以省略的
INSERT INTO stu (id,NAME,sex,birthday,score,email,tel,STATUS) VALUES (2,\'李四\',\'男\',\'1999-11-11\',88.88,\'lisi@itcast.cn\',\'13888888888\',1);
INSERT INTO stu VALUES (2,\'李四\',\'男\',\'1999-11-11\',88.88,\'lisi@itcast.cn\',\'13888888888\',1);
-- 批量添加数据
INSERT INTO stu VALUES
(2,\'李四\',\'男\',\'1999-11-11\',88.88,\'lisi@itcast.cn\',\'13888888888\',1),
(2,\'李四\',\'男\',\'1999-11-11\',88.88,\'lisi@itcast.cn\',\'13888888888\',1),
(2,\'李四\',\'男\',\'1999-11-11\',88.88,\'lisi@itcast.cn\',\'13888888888\',1);修改数据
-
修改表数据
UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 条件] ;注意:
修改语句中如果不加条件,则将所有数据都修改!
像上面的语句中的中括号,表示在写 sql 语句中可以省略这部分
-
练习
-
将张三的性别改为女
update stu set sex = \'女\' where name = \'张三\'; -
将张三的生日改为 1999-12-12 分数改为99.99
update stu set birthday = \'1999-12-12\', score = 99.99 where name = \'张三\'; -
注意:如果update语句没有加where条件,则会将表中所有数据全部修改!
update stu set sex = \'女\';
-
删除数据
-
删除数据
DELETE FROM 表名 [WHERE 条件] ;-
练习
-- 删除张三记录
delete from stu where name = \'张三\';
-- 删除stu表中所有的数据
delete from stu;-
查询多个字段
SELECT 字段列表 FROM 表名;
SELECT * FROM 表名; -- 查询所有数据-
去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;-
起别名
AS: AS 也可以省略
练习
-
查询name、age两列
select name,age from stu; -
查询所有列的数据,列名的列表可以使用 * 替代
select * from stu; -
查询地址信息
select address from stu;从上面的结果我们可以看到有重复的数据,我们也可以使用
distinct关键字去重重复数据。 -
去除重复记录
select distinct address from stu; -
查询姓名、数学成绩、英语成绩。并通过as给math和english起别名(as关键字可以省略)
select name,math as 数学成绩,english as 英文成绩 from stu; select name,math 数学成绩,english 英文成绩 from stu;
条件查询
语法
SELECT 字段列表 FROM 表名 WHERE 条件列表;-
条件
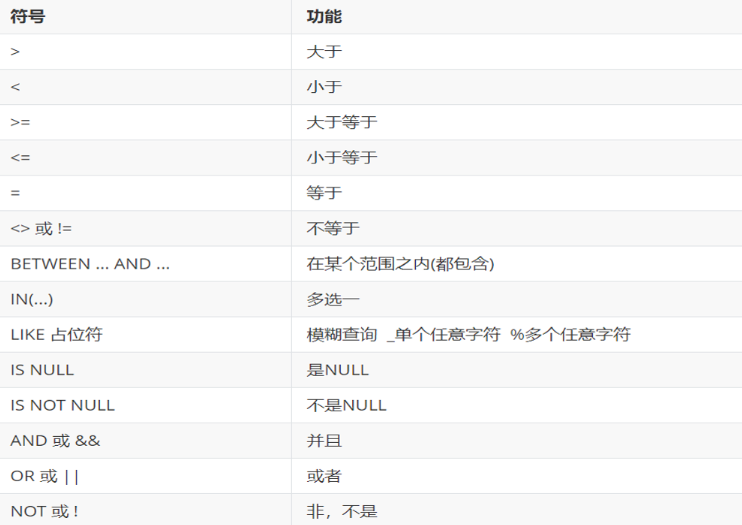
条件查询练习
-
查询年龄大于20岁的学员信息
select * from stu where age > 20; -
查询年龄大于等于20岁的学员信息
select * from stu where age >= 20; -
查询年龄大于等于20岁 并且 年龄 小于等于 30岁 的学员信息
select * from stu where age >= 20 && age <= 30; select * from stu where age >= 20 and age <= 30;上面语句中 && 和 and 都表示并且的意思。建议使用 and 。
也可以使用 between ... and 来实现上面需求
select * from stu where age BETWEEN 20 and 30; -
查询入学日期在\'1998-09-01\' 到 \'1999-09-01\' 之间的学员信息
select * from stu where hire_date BETWEEN \'1998-09-01\' and \'1999-09-01\'; -
查询年龄等于18岁的学员信息
select * from stu where age = 18; -
查询年龄不等于18岁的学员信息
select * from stu where age != 18; select * from stu where age <> 18; -
查询年龄等于18岁 或者 年龄等于20岁 或者 年龄等于22岁的学员信息
select * from stu where age = 18 or age = 20 or age = 22; select * from stu where age in (18,20 ,22); -
查询英语成绩为 null的学员信息
null值的比较不能使用 = 或者 != 。需要使用 is 或者 is not
select * from stu where english = null; -- 这个语句是不行的 select * from stu where english is null; select * from stu where english is not null;
模糊查询练习
模糊查询使用like关键字,可以使用通配符进行占位:
(1)_ : 代表单个任意字符
(2)% : 代表任意个数字符
-
查询姓\'马\'的学员信息
select * from stu where name like \'马%\'; -
查询第二个字是\'花\'的学员信息
select * from stu where name like \'_花%\'; -
查询名字中包含 \'德\' 的学员信息
select * from stu where name like \'%德%\';
排序查询
语法
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;上述语句中的排序方式有两种,分别是:
-
ASC : 升序排列 (默认值)
-
DESC : 降序排列
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
8.3.2 练习
-
查询学生信息,按照年龄升序排列
select * from stu order by age ; -
查询学生信息,按照数学成绩降序排列
select * from stu order by math desc ; -
查询学生信息,按照数学成绩降序排列,如果数学成绩一样,再按照英语成绩升序排列
select * from stu order by math desc , english asc ;
将一列数据作为一个整体,进行纵向计算。
聚合函数分类
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
聚合函数语法
SELECT 聚合函数名(列名) FROM 表;注意:null 值不参与所有聚合函数运算
练习
-
select count(id) from stu; select count(english) from stu;上面语句根据某个字段进行统计,如果该字段某一行的值为null的话,将不会被统计。所以可以在count(*) 来实现。* 表示所有字段数据,一行中也不可能所有的数据都为null,所以建议使用 count(*)
select count(*) from stu; -
查询数学成绩的最高分
select max(math) from stu; -
查询数学成绩的最低分
select min(math) from stu; -
查询数学成绩的总分
select sum(math) from stu; -
查询数学成绩的平均分
select avg(math) from stu; -
查询英语成绩的最低分
select min(english) from stu;
分组查询
语法
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
练习
-
查询男同学和女同学各自的数学平均分
select sex, avg(math) from stu group by sex;注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
select name, sex, avg(math) from stu group by sex; -- 这里查询name字段就没有任何意义 -
查询男同学和女同学各自的数学平均分,以及各自人数
select sex, avg(math),count(*) from stu group by sex; -
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组
select sex, avg(math),count(*) from stu where math > 70 group by sex; -
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2个的
select sex, avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2;
where 和 having 区别:
-
执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
-
可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
分页查询
语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条目数;注意: 上述语句中的起始索引是从0开始
练习
-
从0开始查询,查询3条数据
select * from stu limit 0 , 3; -
每页显示3条数据,查询第1页数据
select * from stu limit 0 , 3; -
每页显示3条数据,查询第2页数据
select * from stu limit 3 , 3; -
每页显示3条数据,查询第3页数据
select * from stu limit 6 , 3;
从上面的练习推导出起始索引计算公式:
起始索引 = (当前页码 - 1) * 每页显示的条数本文来自博客园,作者:link-零,转载请注明原文链接:https://www.cnblogs.com/e-link/p/16964762.html❤❤❤
来源:https://www.cnblogs.com/e-link/p/16964762.html
本站部分图文来源于网络,如有侵权请联系删除。